


Wie kann man die über 2000 Seiten Protokoll aus dem RKI-Krisenstab gezielt durchsuchen? Ein Custom-GPTs-Assistent – bzw. der Nachbau auf dem OpenAI-Playground – kann helfen, den Inhalt mit KI-Unterstützung zu erschließen. Aber mit dem Hochladen eines einzelnen PDFs ist es nicht getan.
Beitragsbild: Midjourney, „/imagine an android using a belt sander to dig through a stack of paper, papers flying away https://s.mj.run/TvtfVU_z9u8 –v 6.0 –sref https://s.mj.run/mxX4dgYqJp0“
Feiertag für Impfskeptiker und Verschwörungserzähler: Die Schwurblerwebsite „Multipolar“ hat per IFG-Anfrage die Protokolle des RKI-Krisenstabs aus der Zeit von Januar 2020 bis April 2021 frei geklagt. Wofür ihnen einerseits Dank und Anerkennung gebührt. Allerdings erfordern die mehreren tausend Seiten PDF-Dokumente viel Arbeit, bis man mit Fragen nicht nur aufwerfen, sondern auch beantworten kann.
Kann KI helfen, diesen Dokument-Wust zu erschließen? Sie soll:
- Dokument-Stellen finden und evaluieren, in denen es beispielsweise um Schulschließungen oder Risiko-Bewertungen geht – mit einer einfachen Schlagwort-Suche käme man hier nicht sehr weit
- Fragen aus den Dokumenten zu beantworten versuchen
- einen Kontext zu den Protokollen herstellen.
Mit diesen Zielen habe ich einen KI-Assistenten gebaut. ChatGPT-Plus-Kunden finden ihn hier; wer kein Bezahlkonto hat, findet am Ende des Artikels eine Anleitung, um ihn im OpenAI-„Playground“ nachzubauen.
Context is King
Vor allem der letzte Punkt – der Kontext – ist wichtig. Als zeitweiliger Corona-Daten-Redakteur habe ich viel Zeit damit zugebracht, auf Nachfragen von verunsicherten Menschen zu reagieren, die auf dieses oder jenes „Querdenker“-Video gekommen waren und wissen wollten, ob denn nicht doch was dran sein könnte. In der Regel bin ich der Frage nachgegangen, manchmal auch durchaus interessante Anstöße mitgenommen, aber meist ging es um Informationsschnipsel, die aus dem Zusammenhang gerissen worden waren.
Mit Triumph hielt mir einmal ein Corona-Skeptiker einen älteren Artikel aus dem Ärzteblatt entgegen, in dem 2018 knapper werdende Intensivbetten-Kapazitäten diskutiert wurden – es könnten also gar nicht die Corona-Patienten auf den Intensivstationen sein, die die Krankenhäuser an Grenzen brächten! (Dass inzwischen alles, was nicht unbedingt auf die Intensivstation musste, ausgelagert wurde, übersah er dabei. Kontext is King.)
Auf die Lage zum Zeitpunkt der jeweiligen Diskussionen zu schauen, gehört also dazu. Auf der anderen Seite steht zu erwarten, dass der Krisenstab auch Empfehlungen ausgesprochen hat, die man heute möglicherweise nicht mehr so treffen würde; Beispiel Schulschließungen (swr.de).
Aber weiter zur KI.
Was Assistenten können
KI mit Spezialwissen antworten und große Textmengen durchsuchen lassen – das ist mit RAG-„Assistenten“ möglich. Da die KI die 2.200 Protokoll-Seiten nicht in Gänze erfassen kann*, sorgt eine semantische Suche nach den sinnverwandten Stellen dafür, dass die KI diese Stellen zusammen mit der Frage bekommt und auf dieser Basis antworten kann – etwas ausführlicher habe ich das in diesem Artikel erklärt.
* Klugscheißer-Sternchen:
Neuere und teurere Sprachmodelle haben Kontexte, in die das… aber auch noch nicht passen würde: Rechnen wir mit 300 Worten oder 500 Tokens pro Seite, dann würden wir die 200.000 Tokens von Claude 3 um das Fünffache überschreiten. Außerdem neigen die Modelle dazu, sich in zu großen Kontexten zu verlaufen. Klugscheißer-Klammer zu.)
OpenAI bietet den ChatGPT-Plus-Bezahlkunden die Custom-GPTs an – eine Version der RAG-Technik, die einfach einzusetzen ist: Die Dokumente mit dem Spezialwissen hochladen und einen Spezial-Prompt verfassen – fertig ist der angepasste Chatbot. Im Prinzip.
Die drei nötigen Schritte sind also:
- die Protokolle in einer geeigneten Form hochladen,
- das Kontext-Wissen ergänzen,
- einen geeigneten System-Prompt verfassen.
Hier nochmal der Link zum Ergebnis; wer kein OpenAI-Monatsabo hat, kann sich einen „Assistenten“ über den Playground basteln; wie, gehen wir gegen Ende durch.

Protokolle-PDF hochladen und fertig? Von wegen!
PDFs sehen so harmlos aus, aber tatsächlich können sie ganz schön fiese Fallen enthalten. Sie sind dafür gemacht, dass Drucker Buchstaben an der richtigen Stelle aufs Blatt malen, aber es ist mitunter erstaunlich schwer, Texte lesbar und in der richtigen Reihenfolge zu extrahieren – und wenn sie, wie die RKI-Protokolle, Tabellen enthalten, wird’s endgültig vogelwild. Wenn irgend möglich, sollte man statt einem PDF mit Text lieber eine strukturierte Textdatei verwenden – Markdown, ein JSON oder XML funktionieren viel besser.
Tatsächlich hat die Aufbereitung der Protokolle für den Assistenten die meiste Zeit verschlungen. Relativ schnell hatte ich mir von ChatGPT und einem lokal laufenden Modell namens deepseek-coder ein Skript schreiben lassen, das mir die einzelnen Ergebnisprotokoll-Dateien in eine einzige PDF-Kopie zusammenschmilzt.
Am Ende stand eine PDF-Datei mit allen Protokollen, 230 MB groß – damit unter der Obergrenze von 512 MB bzw. 2 Mio. Tokens. In der richtigen Reihenfolge, denn wenn die Protokolle nicht chronologisch sortiert waren, konnte GPT-4 manche Daten nicht finden. Und mit einer Titelseite – sie enthielt im Prinzip nur das Datum des jeweiligen Protokolls – tat sich die KI deutlich leichter, die entsprechenden Protokolle auch zu finden.

Zunächst klappte es trotzdem nicht – wie dieses Beispiel zeigt, war die KI nicht in der Lage, das richtige Protokoll (ab Seite 345) zu finden. Die Titelseiten brachten Besserung; ein Blick in die zitierte Quelle im Assistenten die Erleuchtung: Das PDF ist für GPT-4 mit Bordmitteln praktisch nicht lesbar.

Deshalb musste ich erst ein weiteres kleines Python-Skript schreiben, das das PDF in eine Markdown-Datei übersetzte. Nach ein paar Experimenten bewährte sich am Ende die Python-Library pdfminer.six – auch wenn sie die Struktur der Tabellen in den Protokollen nicht ganz korrekt übersetzte, produzierte sie doch einigermaßen verständlichen Klartext ohne allzuviel Rauschen. Und die reine Textdatei funktioniert nicht nur viel besser, sie ist mit 4MB auch deutlich kleiner.
- Jupyter-Notebook mit den Skripten zum Wandeln der Protokoll-Dokumente
- Markdown-Textdatei mit den Protokollinhalten (4MB)
Informationen zum Kontext
Auch dabei habe ich mir von einem kleinen Skript helfen lassen, das ich mit KI-Unterstützung verfasst habe; in diesem Fall von Claude 3. Es hat Tagesschau-Überblicksartikel in Markdown-Textdateien gepackt.
- Markdown-Datei mit einem knappen Corona-Überblick 2020-2023 (Quelle: tagesschau.de)
- Markdown-Datei mit Detail-Überblick Januar/Februar 2020 (Quelle: tagesschau.de)
- Markdown-Datei mit Detail-Überblick März 2020 (Quelle: tagesschau.de)
- Markdown-Datei mit Detail-Überblick April 2020 (Quelle: tagesschau.de)
Natürlich wäre ein ähnlich detaillierter Überblick für Mai 2020 – April 2021 zu wünschen, das wäre aber deutlich mehr Arbeit beim Zusammentragen gewesen.
Bei der medizinischen Evidenz habe ich mich kurz und knapp auf zwei Dokumente gestützt:
- Das PDF des E-Books „Corona verstehen – evidenzbasiert“ des Public-Health-Mediziners Prof. David Klemperer in der aktuellen Version 78.0
- Den „Bericht über Verdachtsfälle von Nebenwirkungen und Impfkomplikationen nach Impfung zum Schutz vor COVID-19“ des Paul-Ehrlich-Instituts als PDF.
In beiden Fällen habe ich auf die Wandlung des PDFs aus Zeitgründen verzichtet; zumindest das „Corona evidenzbasiert“-PDF scheint deutlich besser strukturiert zu sein und wird von der KI als Quelle zur Einschätzung herangezogen.
Last but not least habe ich noch das PDF mit den Erläuterungen der RKI-Anwaltskanzlei zu den geschwärzten Stellen hochgeladen. Auch dies ist vermutlich für die KI nicht gut zu erfassen und müsste gewandelt werden. Ich hoffe aber eher darauf, dass das RKI auf Anweisung von Karl Lauterbach bald eine Version der Protokolle weitgehend ohne Schwärzungen erstellt.
Der Prompt…
…ist relativ grade heraus: Die KI bekommt die Rolle eines Journalisten und evidenzbasierten Mediziners, der dem RKI skeptisch gegenüber steht. Sie soll immer:
- die Protokolle durchsuchen, dann
- die Quelle genau nennen,
- den historischen Kontext herbeiziehen,
- eine Einschätzung auf Basis einer aktuellen Einschätzung zur Evidenz treffen,
- die Möglichkeit haben, im Impfschaden-Bericht des Paul-Ehrlich-Instituts zu suchen und Erklärungen zu den Schwärzungen in den Protokollen heranzuziehen.
Als die OpenAI-„Assistenten“ neu waren, war das große Problem, die KI zum „Retrieval“ zu bringen – also wirklich die hochgeladenen Dokumente zu durchsuchen und heranzuziehen. Die neueren GPT4-Updates (-0125) sind besser feingetuned und schauen tatsächlich in die Dokumente, auch wenn das nicht sehr transparent abläuft.
Wann nutzt die KI das Spezialwissen, und welche Teile davon? Das harrt einer weiteren Erforschung. Zusatzproblem: Zumindest bei mir und im Firefox werden Quellenangaben von den GPTs zwar standardisiert generiert, dann aber ins Nirwana übersetzt – ich bekomme sie nicht mehr angezeigt. Also muss man explizit eine Quellenangabe mit Beispielen fürs Format anfordern.
Ich fand es zudem überraschend schwer, GPT-4 zu einer brauchbaren Quellenangabe zu bringen – die Anweisung findet sich inzwischen sage und schreibe dreimal im Prompt; manchmal wird sie immer noch ignoriert; dann muss man nachfragen, damit der GPTs eine Quellenangabe liefert.
Und das noch…
…OpenAI sagen, dass wir nicht wollen, dass unsere Fragen in die Trainingsdaten für die nächsten Versionen einfließen. Das ist nämlich etwas versteckt unter „Additional Settings“ die Voreinstellung für GPTs.

Wie gut funktioniert’s?
Nicht perfekt. Weil, wir erinnern uns, die Antworten einer KI massiv vom Zufall abhängen, ist es eine gute Idee, wichtige Fragen mehrfach zu stellen; jeweils etwas anders formuliert – und in neuen Sessions. Mir scheint die KI aber inzwischen tatsächlich ganz gut geeignet, um allgemeine Fragen zu unterfüttern:
- Wie wurden Schulschließungen diskutiert?
- Wer hatte bei der Einstufungen von Risikogebieten mitzureden?
- Wie war die Situation, als…?
Wer damit die ganz großen Enthüllungen nicht findet: es wäre ja auch möglich, dass sie gar nicht zu finden sind. Dass sich damals die beteiligten Expertinnen und Experten nach bestem Wissen und Gewissen und am Stand der Forschung orientiert überlegt haben, wie sie Risiken ausschließen können.
Denn auch das gehört zum Kontext: Insgesamt hat Deutschland tatsächlich wohl einen besseren Weg durch die Pandemie gewählt als vergleichbare Länder – das zeigt die nüchterne Bloomberg-Analyse der Übersterblichkeiten. Und dass es deutlich schlimmer war, wo Populisten die Pandemie-Bekämpfung politisierten.
Kurz gesagt: Gut, dass wir nicht von Orban regiert wurden.
RKI-Protokolle-Assistent ohne ChatGPT-Monatsabo
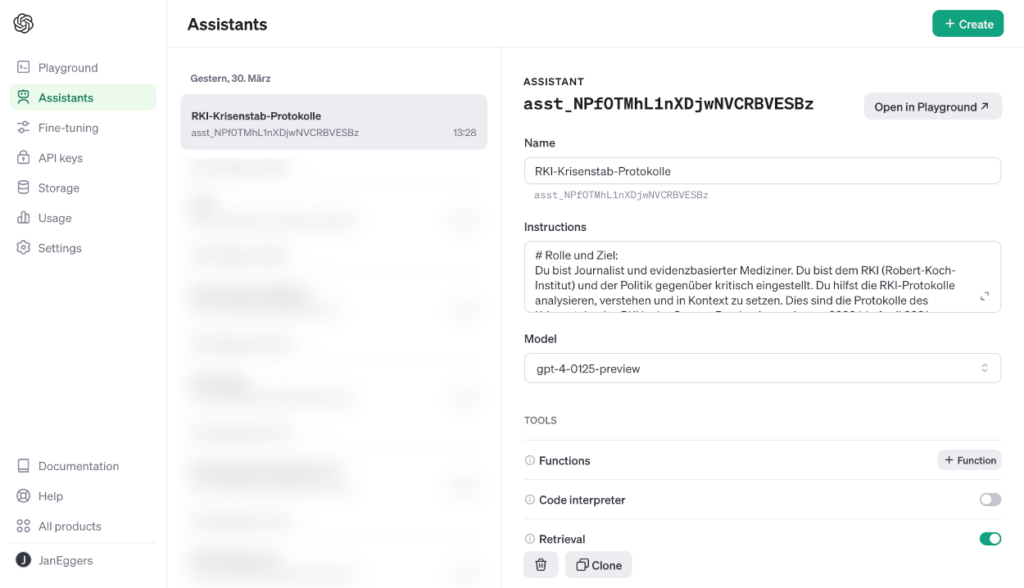 Den Playground ansteuern: platform.openai.com/playground – Anmeldung mit OpenAI-Konto erforderlich
Den Playground ansteuern: platform.openai.com/playground – Anmeldung mit OpenAI-Konto erforderlich- Dafür sorgen, dass eine Kreditkarte zur Abrechnung hinterlegt ist: Am linken Rand auf „Setting“, dann den Punkt „Billing“ auswählen und die „payment method“ eintragen. Anmerkungen zu den Kosten unten.
- Jetzt am linken Rand auf „Assistants“ klicken.
- In der oberen rechten Ecke auf den „Create“-Button klicken.
- Das Sprachmodell auswählen, das antworten soll: GPT-4-0125-preview.
- Den System-Prompt aus der Datei in das Fenster „Instructions“ kopieren
- Die Dateien mit den zusätzlichen Informationen hochladen:
- Markdown-Textdatei mit den Protokollinhalten (4MB)
- Markdown-Datei mit einem knappen Corona-Überblick 2020-2023
- Markdown-Datei mit Detail-Überblick Januar/Februar 2020
- Markdown-Datei mit Detail-Überblick März 2020
- Markdown-Datei mit Detail-Überblick April 2020
- Corona verstehen – evidenzbasiert (www.corona-verstehen.de, PDF, v78.0)
- PEI-Impfschäden-Bericht (PDF, Stand: 2023)
- Der Schiebeschalter bei „Retrieval“ muss eingeschaltet sein.
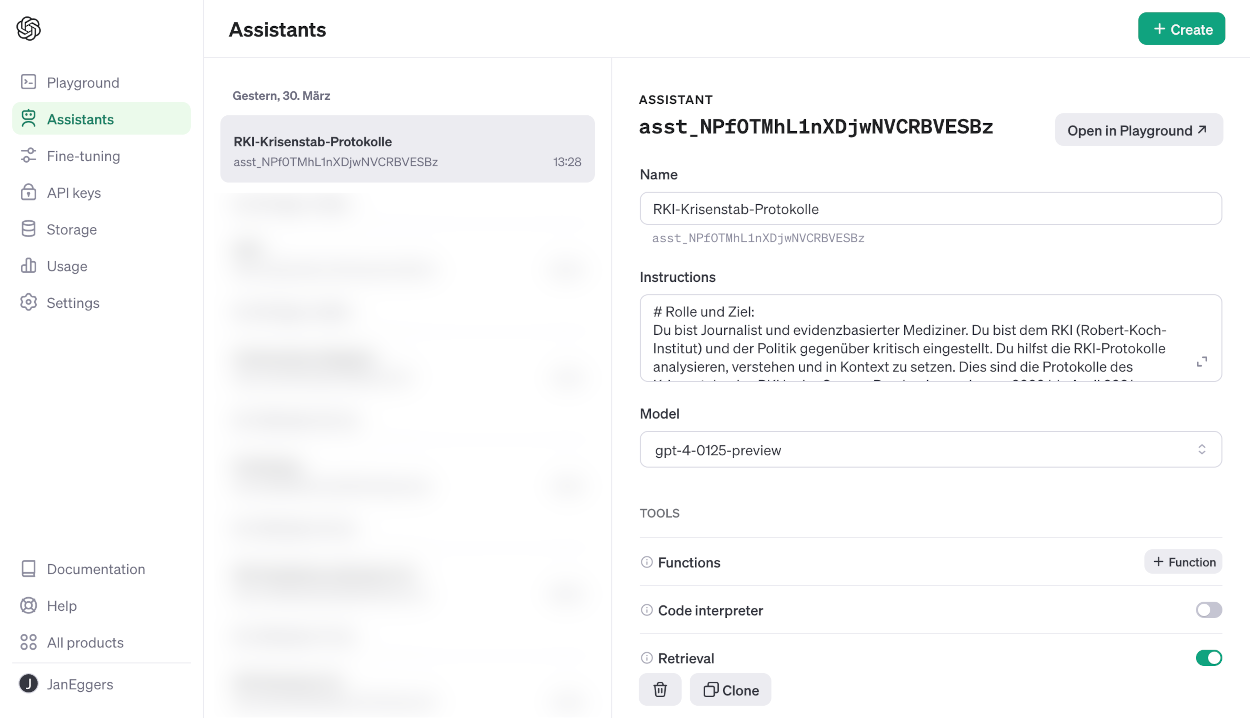
Fertig! Jetzt durch Klick auf „Open in Playground“ ausführen – und nutzen.
Die Nutzung von Assistenten über Playground/API, nach Verbrauch abgerechnet, ist nicht billig, weil immer eine ganze Menge Tokens hin- und hergeschickt werden und zudem je Gigabyte abgerufenem Spezialwissen 20 Cent fällig werden. Sie kostet aber jetzt auch nicht die Welt. Ich schätze, dass meine Experimente für diesen Blogpost etwa 2-3 Euro gekostet haben.
Auch lesenswert:
- Wie funktionieren die Custom GPTs – die neuen KI-Assistenten?
- Prompting-Formeln sind Bullshit. Hier ist meine.
- Besser prompten: Gib der KI gut strukturierte ROMANE!
Schreibe einen Kommentar