


Vor einem Jahr suchte ich nach einer Formel, um Tipps für bessere Prompts zu geben, und fand: ROMANE – ein Merkwort für Ansätze für bessere Anweisungen an eine KI. Zeit für eine kleine Bilanz: funktioniert das wirklich so?
Nichts ist so dauerhaft wie ein Provisorium. Es war nach einem Seminar für NDR extra3 – bei dem ich echt viel gelernt habe, weil es die Jungs und Mädels dort in jeder Hinsicht ziemlich drauf haben – dass mich Anne-Kathrin Gerstlauer ansprach, die Autorin des wunderbaren „TextHacks“-Newsletters: Nie mehr mittelmäßige Texte schreiben! Das sollte auch für Prompts gelten, und sie fragte mich, ob ich meine besten Tipps fürs Prompten nicht in einen kompakten Newsletter-Post packen könnte.
Also habe ich die wichtigen Dinge mit nackter Gewalt in die Anfangsbuchstaben eines Merkworts gepresst: Rolle, Objective, Meta-Anweisungen, Anwendungsbeispiele, Nützliches, Empfänger, kurz: ROMANE. Damit war ich zwar nicht so glücklich, schon wegen des etwas gequälten englischen Worts „Objective“ für „Zielsetzung“ nicht (bring du mal ein Z irgendwo unter, Scrabble-King!), aber es half mir beim Schreiben, deshalb durften die ROMANE bleiben. Vorerst. Bis mir was Besseres einfällt. Und dann verging ein Jahr, in dem ich die ROMANE-Formel in dutzenden Seminaren vorgestellt und benutzt habe – einfach weil sie sich gut eignet, wichtige Konzepte für KI-Prompts zu vermitteln.
Was seitdem geschah…
Ein Jahr ist viel Zeit, besonders, wenn es um KI geht. Kleiner Flashback: Im August 2023, da war GPT-4 noch beschränkt auf Bezahlkunden, da gab es noch keine GPTs-Asisstenten, ChatGPT-Konkurrent Claude war in Deutschland nicht verfügbar, bei den Bildgeneratoren kämpften Midjourney-5 und das damals neue DALL-E3 um die Krone; Bildgeneratoren wie Runway oder Song-Generatoren wie Suno existierten noch nicht.
Und in diesem Jahr ist eine ganze Menge Forschung über Sprachmodelle dazugekommen. Unter anderem eine Überblicks-Studie aus dem Juli 2024 (Schulhoff, Ilie, et al., „The Prompt Report: A Systematic Survey of Prompting Techniques“) , die auf über 70 Seiten systematisiert, was in anderen Studien über nützliche Prompting-Techniken zu finden ist — und in zwei Fallstudien mit GPT-3.5-Turbo testet, was wie gut wirkt. Sie liefert eine ganz gute Basis, um einzuschätzen, was Aberglaube oder überflüssig ist – und was aus Sicht der KI-Forschung wirklich etwas bringt.
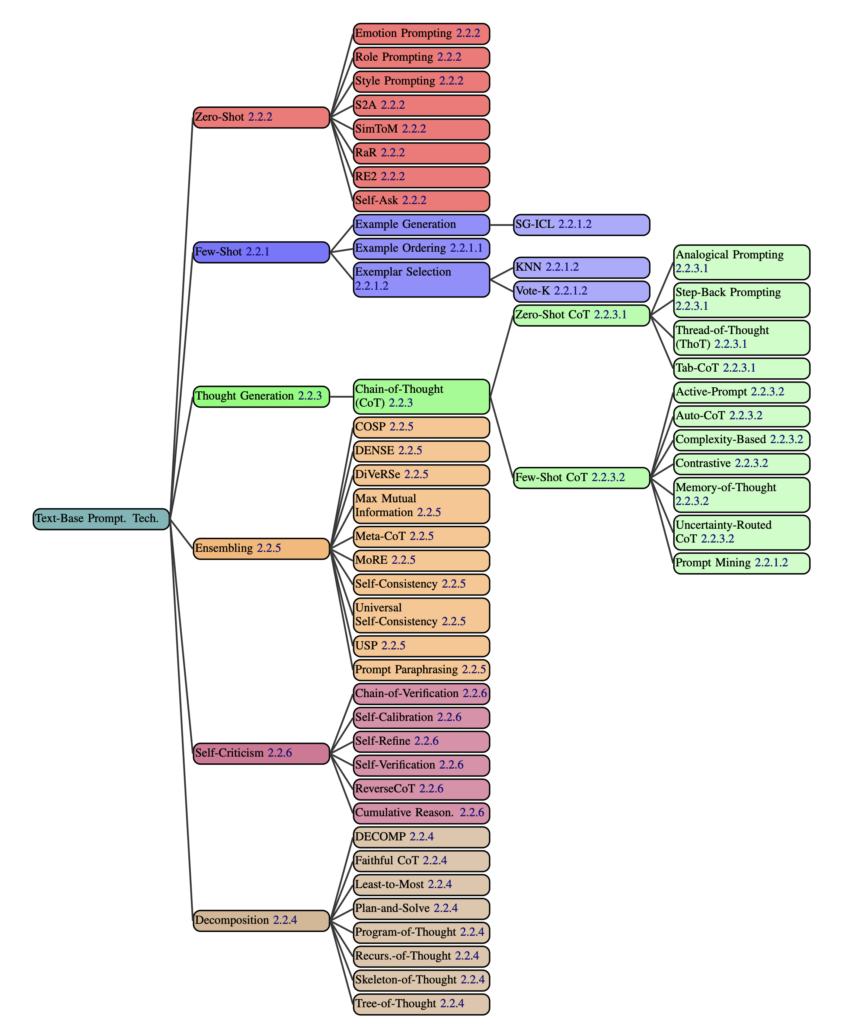
Also: Was hat sich bewährt, was fehlt in der ROMANE-Formel?
Die Klassiker: Rolle und Zielsetzung
Lass die KI ein Rollenspiel spielen! „Du bist ein Marketing-Stratege“, „Sei die Assistentin der Geschäftsleitung“, oder – als umgekehrtes Rollenspiel – „Schreibe, als ob ich fünf Jahre alt wäre“, „Schreibe, um eine Strafrechts-Klausur zu bestehen“. Der Geheimtipp aus der ChatGPT-Frühzeit ist inzwischen common sense – und der Forschungsüberblick zeigt, dass viele Ansätze darauf erfolgreich aufbauen: Bessere Ergebnisse für ergebnisoffene Aufgaben und leichte Verbesserungen bei standardisierten Aufgaben.
Meine eigenen Erfahrungen: Eine Rolle ist einfach eine effiziente Methode, um der KI einen Kontext zur Aufgabe zu geben – schließlich kann sie die Gesprächssituation nicht wie ein Mensch erfassen. Sie sind ein gutes Gegenmittel gegen ChatGPTs flachen, inhaltsleeren Standardstil. Aber natürlich kann die Rolle auch in die falsche Richtung führen – wenn die Rolle ist: Schreib wie ein Moderator, dann kann man fast darauf wetten, dass die KI ihren Text mit einer Begrüßung beginnt. Obskure Rollen – sei ein Reliquienschnitzer! – führen zu Halluzinationen, übertriebene – sei die intelligenteste Person in diesem Sonnensystem! – erzeugen keine besseren Ergebnisse.
Dass man der KI genau beschreiben muss, was sie für uns tun soll, ist klar. Aber wie beschreibt man denn nun Ziele am besten? Die Wissenschaftler raten dazu, Anweisungen eher klar zu formulieren und auf wolkige Formulierungen zu verzichten; das findet sich im Wort „Objective“ einigermaßen wieder – weshalb ich denke: Das R und das O funktionieren eigentlich ganz gut. Auch wenn sie ziemlich banal sind.
Meta-Anweisungen: Sag der KI, wie sie arbeiten soll
„Gehe Schritt für Schritt vor“ – auch das ist ein Tipp aus der ChatGPT-Frühzeit, der inzwischen den Rang einer Binsenweisheit hat. Genau das hatte ich ursprünglich mit dem M für „Meta-Anweisungen“ gemeint – auf wissenschaftlich heißt das Chain-of-Thought-Prompting, dass es funktioniert, ist gut belegt, und es gibt unzählige Varianten mit wundervollen Namen — zum Beispiel „Thread-of-thought“ („Führe mich Schritt für Schritt durch diesen Kontext, in gut verarbeitbaren Brocken, und fasse alles zusammen und analysiere, während wir vorangehen“), „Plan-and-solve“ („Versuche zunächst das Problem zu verstehen und schlüssele es in einzelne Schritte auf, entwickele dann einen Plan um es zu lösen“) oder „Step-back-prompting“ (erst schiebt man eine allgemeine Frage zum Thema ein, um den Kontext zu setzen, dann stellt man die spezifische Frage). Oder als Anwendungsfall der „Chain-of-Verification“-Ansatz von Patrick Große, wenn man Fakten prüfen lassen will.
Der Grundgedanke ist, dass man die KI dazu bringen muss, Konzepte in Token zu fassen — gewissermaßen (Achtung, Vermenschlichungsalarm!!!) laut zu denken. Und „Chain-of-Thought“ ist nur eine Umsetzung dieser Grundidee. Da wären Prompts, die die KI die Problemstellung wiederholen lassen: „Formuliere und erläutere das Problem in deinen eigenen Worten, bevor du antwortest“ („Reprase-and-respond“, RaR), „Entscheide, ob du genug über das Problem weißt, und formuliere dann Fragen“ („Self-Ask“), oder, ebenso schlicht wie effektiv: „Zitiere die Frage noch einmal“ („Re-Reading“, RE2).
Alles, was die KI auffordert, die eigene Antwort zu bewerten und zu verbessern — „Bewerte deine Antwort und gib auf einer Skala von 1 bis 10 an, wie sehr du ihr vertraust“ („Self-Critique“) — könnte man ebenso unter „Meta“ fassen wie alle Ansätze, die das Problem in Teilaufgaben aufgliedern („Decomposition“), und die auch sehr schöne Namen haben: beispielhaft sei „Least-to-most-prompting“ genannt (Zerlege ein Problem in Teilaufgaben, ohne sie zu lösen. Löse dann Teilaufgabe 1, Teilaufgabe 2 und so weiter – bis du schließlich das gesamte Problem abschließend lösen kannst).
Kleiner Einwand aus der Praxis: Wenn ich der KI haarklein und in jedem Detail erklären muss, wie das Problem zu lösen ist, kann ich es eigentlich auch gleich selbst machen. Der KI-Forscher Subbarao Kambhampati argumentiert, dass Chain-of-Thought eigentlich nur funktioniert, wenn ich die Lösung des Problems schon kenne (hier bei Xitter), und da er unter anderem sehr clevere Experimente designt, in denen Klötzchen umzuschichten sind, und bei denen sich die KI regelmäßig blamiert, sollte man das ernst nehmen. In jedem Fall sollten wir die KI nicht für schlauer halten als sie ist: Symbolisch denken, generalisieren und daraus logische Schlüsse ziehen – das können Sprachmodelle eigentlich nicht.
Zurück zum Nutzen des „M“ in der ROMANE-Formel. Dass „Meta…“ ein reichlich unscharfer Begriff ist, hat sich als sehr nützlich erwiesen. Andererseits steckt dadurch vielleicht einfach zu viel in diesem einen kleinen Buchstaben drin, um als Merkwort nützlich zu sein.
Geheimwaffe A – der KI Anwendungsbeispiele geben
Prompts, die der KI ein Beispiel zeigen, sehe ich erstaunlich selten – dabei ist die Technik alles andere als neu: „Language Models are Few-Shot Learners“ – das klassische Forschungspapier dazu stammt aus dem Jahr 2020 und beschreibt, dass Beispiele im Prompt – in KI-Sprech: „shots“ – das Ergebnis bei vielen Aufgaben deutlich verbessern.
Wie viele Beispiele sollen es sein? Ältere Sprachmodelle wie Aleph Alpha haben mit zwei „shots“ gute Ergebnisse erzielt, die Meta-Studie schränkt nur ein, es sollten vielleicht nicht mehr als 20 sein – und bemerkt, dass es sich auch hier lohnt, zu experimentieren: Die Reihenfolge der Beispiele scheint ebenso eine Rolle zu spielen wie die Wahl der Beispiele selbst. Die Meta-Studie ist ein guter Ideengeber. Warum nicht neben einem Beispiel für eine korrekte Bewertung ein Beispiel für einen Fehlschluss aufführen – als „Contrastive CoT Prompt“? Scheint besonders für Faktenfragen gut zu funktionieren. Also: Probieren – und testen!
Jedenfalls: Das „A“ in der ROMANE-Formel ist wichtig, gerade weil viele Menschen nicht auf dem Schirm haben, wie mächtig diese Technik ist. Aber das kann nicht mehr sein als ein Einstieg; ähnlich wie bei den Meta-Prompts verbirgt sich dahinter eine verwirrende Anzahl möglicher Ansätze und Techniken, die man am Ende für sich selbst erkunden muss.

Was ROMANE leider nicht erfasst: das Wichtigste, was man über KI wissen muss
Tatsächlich fehlt in den ROMANE-Merkworten das Wichtigste, was ich über KI zu sagen habe: Wenn ein Prompt nicht gleich den gewünschten Erfolg bringt, liegt es nicht unbedingt an dir – es kann einfach Pech sein. Die Ergebnisse von generativer KI sind stark zufallsabhängig; das sind wir von Computern so nicht gewohnt, deshalb unterschätzen wir, wie stark die Ausgabe einer KI von Versuch zu Versuch schwankt (was ziemlich drastische Folgen haben kann, aber das ist ein anderes Thema).
Überhaupt ist es ja oft am besten, sich den Ergebnissen Schritt für Schritt zu nähern – und auch das fehlt in der ROMANE-Formel: die Empfehlung, sich an Lösungen heranzutasten, Verbesserungen von der KI zu erfragen, iterativ zu arbeiten – und die Ergebnisse systematisch zu testen: Wenn die KI beispielsweise die Qualität eines Nachrichtentextes beurteilen oder eine Nutzermail klassifizieren soll, ist es eine gute Idee, Beispiele und gewünschte Ergebnisse zu einem Testdatensatz zusammenzufassen und Prompts daran zu messen – Werkzeuge wie die Testoberfläche Chainforge helfen dabei, sind aber zugegebenermaßen ein klein wenig nerdig.
Was im ROMANE-Merkvers noch fehlt
Wer häufiger mit KI-Prompts zu tun hat, wird im Anwendungsbeispiele-Abschnitt gezuckt haben bei der Erwähnung von Prompts mit 20 Beispielen. Und das nicht nur, weil 20 gute Beispiele ja auch erst mal vorbereitet sein wollen. Tatsächlich sollten Prompts nicht zu lang werden, auch wenn die immer größeren Kontextfenster moderner Sprachmodelle dazu verleiten: Die Ergebnisse werden nachweislich schlechter, und Sprachmodelle neigen dazu, den Mittelteil eines Prompts weniger stark zu beachten oder ganz zu übersehen. (Liu et al., „Lost in the Middle“, Mo Li et al., „NeedleBench“) Weshalb ich ernsthaft überlege, das „N“ in ROMANE künftig als „Nicht zu lang“ zu interpretieren.
Wobei es manchmal durchaus zu helfen scheint, der KI etwas mehrfach zu sagen – das haben die Macherinnen und Macher der Prompting-Metastudie mehr oder weniger durch Zufall entdeckt, als sie aus Versehen eine Anweisung im Prompt wiederholten und deutlich bessere Ergebnisse bekamen. Was das Papier zu dem Stoßseufzer verleitet, Prompting bliebe am Ende dann doch eine schwer zu erklärende schwarze Kunst. Sprich: wie eine Änderung am Prompt das Ergebnis beeinflusst, ist nicht zuverlässig vorherzusagen.
Und damit sind wir wieder beim Testen – und der Notwendigkeit, einen weiteren ROMANE-Buchstaben umzuinterpretieren: „E“ für „Experimentieren“, als Erinnerung, dass man immer auch schauen muss, wie kleine Änderungen das Ergebnis beeinflussen.
Was im ROMANE-Merkvers immer noch nicht fehlt
Und wie sollen wir mit der KI reden – im Kommandoton, möglichst nüchtern und sachlich, möglichst höflich? Die Frage führt in ein Rabbithole, in das ich neulich abgestiegen bin – mit dem Ergebnis, dass mich das alles nicht überzeugt: Es gibt m.E. keinen schlüssigen Beweis, dass höfliche, appellierende, drohende oder belohnende Prompts wirklich substanziell besser funktionieren. Also kein neuer Buchstabe dafür – wobei: „BROMANE“, mit „B“ für: Bitten, betteln, bestechen, bedrohen — das hätte ja auch was.
Und was wird jetzt aus der ROMANE-Formel?
Okay, ich geb’s zu: Systematisch taugt „ROMANE“ nur so mittelprächtig. Eigentlich tragen nur die ersten vier Buchstaben wirklich Gewicht, dabei sind R und O trivial, M und A total überladen, N und E in der bisherigen Form verzichtbar, und das Merkwort ist ergänzungsbedürftig. Auch in der überarbeiteten Form, bei der N für „Nicht zu lang“ und E für „Experiment“ steht.
Aber am Ende geht es vor allem darum, Menschen klarzumachen, dass sie eben nicht mit einer menschenartigen Intelligenz kommunizieren, sondern Daten in ein technisches System eingeben, das nach eigenen Regeln spielt. Forschern ist schon ziemlich früh aufgefallen, dass wir Menschen beim Dialog mit der KI den Fehler machen, sie nach ähnlichen Maßstäben zu beurteilen wie ein menschliches Gegenüber. Der Mensch kann etwas, oder er kann es eben nicht – wenn eine KI im ersten Versuch anders antwortete als erwünscht, neigten Testpersonen dazu, aufzugeben – anstatt das Problem leicht umzuformulieren und es nochmal zu probieren. (Youtube-Video zu den Studienergebnissen). Wir neigen dazu, KI zu vermenschlichen, und das zu durchbrechen: dabei bleibt die ROMANE-Formel ein nützliches Werkzeug.
Nicht, dass ich jetzt noch von ihr wegkäme.
Nichts ist so dauerhaft wie ein Provisorium.
Schreibe einen Kommentar