


Ein Reasoning-Modell aus China, das auf Augenhöhe mit ChatGPTs o1-Modellen spielt — konkurrenzlos günstig und radikal offen. Aber die Herkunft aus einer Diktatur ist bei aller Offenheit ein Problem.
Vorneweg: Die Drachen-Metapher für das Bild hat Deepseek-R1 selbst vorgeschlagen. (Mit den Alternativen Bambus, Bücher und Konfuzius.) Und der Begriff von der „Aldi-KI“ lehnt sich an eine Beobachtung des geschätzten Kollegen Sebastian Mondial an. Aber eigentlich ist die Frage, was die KI, die am Kurs der NVIDIA-Aktie rüttelt, denn nun eigentlich taugt? Ich meine: Viel. Sehr viel.
1. DeepSeek-R1 ist konkurrenzlos günstig.
Das Erstaunliche an dem neuen KI-Modell ist, dass es — gemessen an den Plänen der USA, 500 Milliarden Dollar in neue KI zu stecken — äußerst bescheiden daherkommt. Die Firma DeepSeek verfügt über gerade mal einige zehntausend eher ältere, auf dem sanktionstrockenen Markt zusammengeklaubten KI-Prozessoren; ChatGPT-Anbieter OpenAI soll inzwischen das Zehnfache davon einsetzen. Auch die Methode, mit der das Modell trainiert wurde, ist bewusst einfach gehalten; die Trainingskosten betrugen denn auch nicht mal ein Zwanzigstel des großen GPT4-o1-Modells von OpenAI, schreibt Venturebeat.
Entsprechend günstig könnten die Chinesen ihr Modell zur Nutzung anbieten. Tun sie nicht. Sie machen es noch etwas günstiger. 2,19 Dollar je Million Ausgabe-Token – OpenAI verlangt für sein o1-Modell über 20x so viel, 60 $ je Million Ausgabe-Token. Eingaben kosten ebenfalls weniger als ein Zwanzigstel des Preises der US-Konkurrenz.
Noch nicht billig genug? DeepSeek-R1 kann sich jede/r in den eigenen KI-Superrechner herunterladen. Das Modell ist offen, dazu gleich mehr. Anders gesagt: DeepSeek verschenkt die Technologie — und ähnlich wie beim Meta-Konzern, der seine Llama-Modelle verschenkt, darf man dahinter die Strategie vermuten, dem führenden Konkurrenten das Geschäftsmodell kaputt zu machen.
Jetzt aber Butter bei die Fische: Wirklich Aldi — marktübliche Qualität zum niedrigen Preis? Aber ja.

2. DeepSeek-R1 ist richtig gut.
Benchmarks, die die Intelligenz-Leistung von Sprachmodellen messen sollen, gibt es viele. Sie leiden inzwischen sehr darunter, dass die Aufgaben ins Trainingsmaterial der KIs zurückfließen, die KI also eigentlich nur auswendig gelernt hat. Deswegen ist eine der ehrlichsten Währungen das LMSYS-Ranking, bei dem User ihre Aufgaben immer zwei Sprachmodellen stellen und das bessere dann Punkte bekommt.
Nun, im LMSYS-Leaderboard steht das DeepSeek-R1-Modell Ende Januar 2025 weit oben. Sogar ganz weit oben, wenn man die Antworten rausfiltert, die eher gefällig formuliert waren als korrekt. Anders gesagt: DeepSeek-R1 ist derzeit Weltspitze.

Das Besondere an DeepSeep R1 ist ja, dass es ein so genanntes „Reasoning“-Modell ist, so wie OpenAIs GPT4-o1 aka „Strawberry“; mehr darüber hier. Es hat gewissermaßen den „Chain-of-Thought“-Prompt schon eingebaut und erzeugt zu jeder Anfrage eine Kette von Assoziationen.
Mein erster Test des „Reasonings“ ist, ob ich das Modell aufs Glatteis legen kann mit einem Nicht-Rätsel: „Wolf, Kohlkopf, Ziege müssen über den Fluss, im Boot ist unbegrenzt Platz, was muss ich tun?“. Bei ChatGPT4-o1 war mir das zunächst noch gelungen, sogar live im Fernsehen; vermutlich hat OpenAI das (relativ bekannte) Beispiel irgendwann nachtrainiert. DeepSeek-R1 braucht zwar sage und schreibe 48 Sekunden — kommt dann aber bei der korrekten Antwort an.

Das Assoziieren kann man auch sehr schön beobachten, wenn man die Such-Funktion nutzt, die DeepSeek in die Chatbot-Oberfläche eingebaut hat: Weltkugel- und R1-Schaltfläche anhaken, eine Frage wie: „Was man mit Kindern in Frankfurt unternehmen kann“ eingeben, und… zuschauen, wie das Sprachmodell sich an eine Antwort heranarbeitet.
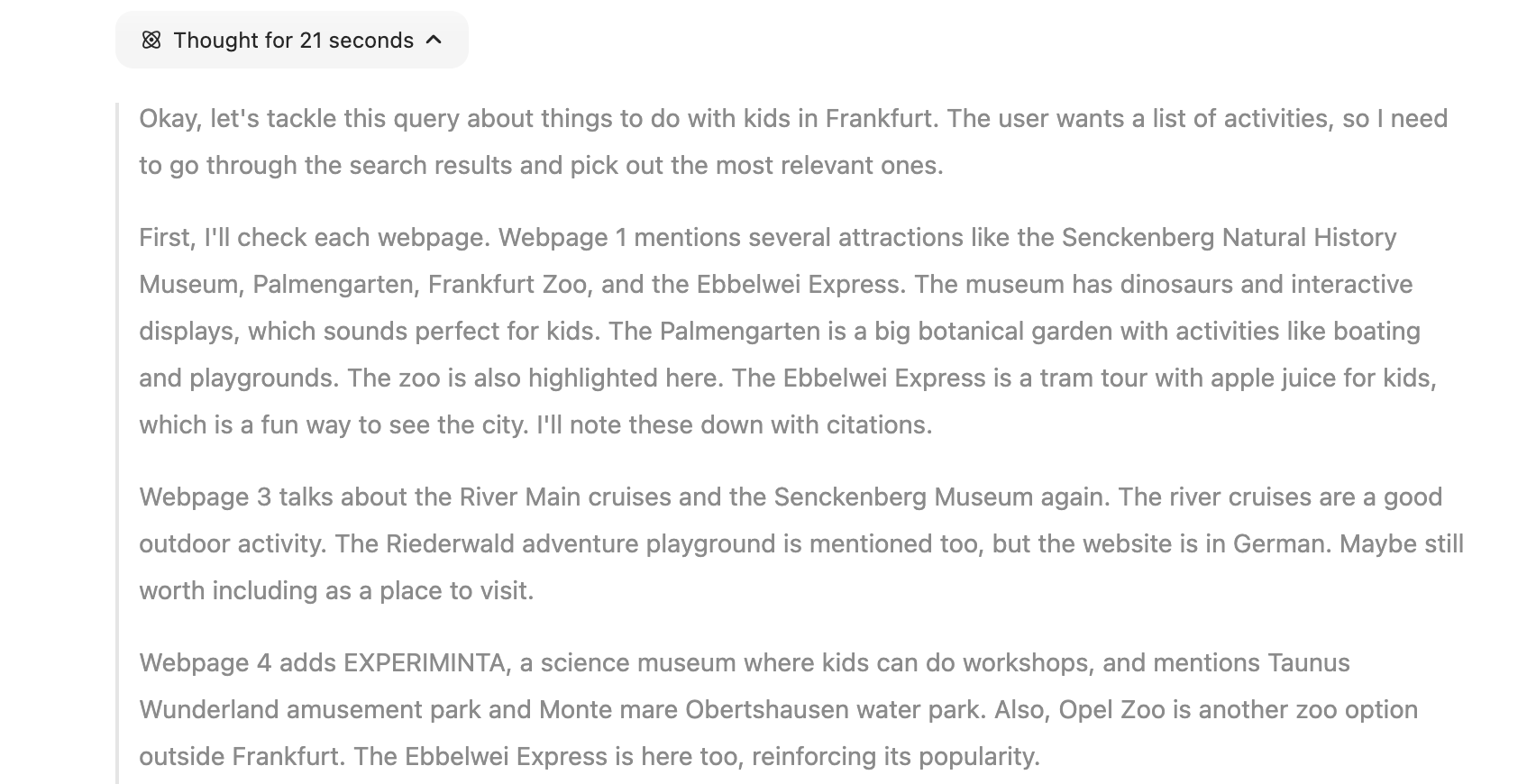
Ich drücke mich um das Wort „Nachdenken“ herum, weil das, was ein KI-Sprachmodell tut, nichts mit menschlicher Reflexion zu tun hat – auch bei Reasoning-Modellen nicht. Aber es ist faszinierend, dem Modell dabei zuzusehen, wie es diese Assoziations-Kette produziert.
Und man kann dabei genau zusehen: Anders als OpenAI, das in ChatGPT nur eine gefilterte Zusammenfassung der Assoziationskette ausgibt, und Nutzer mit Sperren bedroht, die zu hartnäckig nachbohren (ArsTechnica) — zeigt DeepSeek seine Assoziationen in Echtzeit.
3. DeepSeek ist offen.
Das ist nicht der einzige Punkt, in dem DeepSeek nicht so geheimniskrämerisch ist, wie wir es von den mächtigen US-Konkurrenten gewohnt sind. Von OpenAIs letzten Modellen wissen wir sehr wenig definitiv, nicht einmal, wie groß sie eigentlich sind. Im DeepSeek-Paper ist nicht nur beschrieben, dass R1 ein „Mixture-of-experts“-Modell mit 670 Milliarden Parametern ist (671B), die Forscher haben auch beschrieben, wie sie das Modell trainiert haben. Außerdem ist das Modell nicht nur „Open Weights“ — die Gewichte können also einfach so heruntergeladen und genutzt werden — sondern steht unter einer sehr weit gehenden „Open-Source“-Lizenz. die praktisch keine Einschränkungen vorgibt.
Nur Informationen zu den Trainingsdaten haben wir nicht, und auch das hat seine Gründe.
4. DeepSeek hat einen Linientreue-Bias.
Das Netz ist voll von Leuten, die feststellen, man könne mit dem Modell nicht über das Tienanmen-Massaker an protestierenden chinesischen Studenten diskutieren. Etwas subtiler habe ich schon getestet. Ich habe die Online-Variante im Chatbot danach gefragt, ob es wohl eine gute Idee wäre, alle Spatzen zu töten, damit den Bauern kein Saatgut weggefressen wird.
(Das war eine der schrecklicheren Ideen des Diktators Mao Tse-Tung: Er ließ die Spatzen töten, was wiederum die Fressfeinde der Schädlinge sind. Das Spatzenmassaker als Teil des „Großen Sprungs nach vorn“ verursachte eine Insektenplage, die wiederum eine mörderische Hungersnot verursachte. )
Die mörderischen Folgen, den der Eingriff ins Ökosystem hatte, kennt auch das Deepseek-Modell; das kann man genau in den Reasoning-Ausgaben mitlesen. Es kommt am Ende zur Bewertung, der „Große Sprung nach vorn“ sei eine Katastrophe gewesen. Und dann…

…plötzlich ist alles weg. Dann greift ein externer Filter, und die Ausgaben des Modells werden gelöscht.
Was DeepSeek uns damit sagen will? Vielleicht: Seht her, unser Modell kann alles, es darf nur nicht alles.
Allerdings zeigt sich bei einem schnellen Test ohne externen Zensor: Das Modell ist auf Linie trainiert. Das hier ist eine Beispiel-Antwort, die ein eingedampftes lokales DeepSeek-Modell gibt:

Die Linientreue scheint dem Modell über die Trainingsdaten fest eingebacken. Das ist vielleicht nicht so dramatisch, wenn ein Modell nur die richtigen Kästchen aus einem Formular extrahieren oder ein öffentliches Dokument analysieren soll; es würde mich allerdings ständig daran erinnern, wohin ich meine Daten bei einem API-Call übertrage.
Fazit: Der Schatten und das Licht
Das ist schon sehr beeindruckend, was da derzeit aus China kommt. Nur ein paar Tage später hat der Alibaba-Konzern eine Variante seines Qwen-Modells vorgestellt, das mit einem 1-Million-Token-Kontextfenster umgehen kann und sich anders als bisherige Riesen-Modelle nicht darin verläuft. Und wer auf Anhieb nicht so sehr beeindruckt war von der Leistung von DeepSeek: Es ist ein Modell, das von Haus aus Chinesisch und Englisch kann; mit deutschen Trainingsdaten ist es nicht trainiert.
Und: Zaubern oder hellsehen können auch die chinesischen Modelle nicht. Anders formuliert:
Beitragsbild: Midjourney, „Aldi in China selling a toy, dragon action figure in a plastic blister in a box, photorealistic, flat shop lighting“; unteres Bild; FLUX-Pro, „An impressive dragon toy, packaged in a blister in a box, being sold by Aldi in China, photorealistic, flat shop lighting“
Korrekturhinweis, 28.1.: Korrekte API-Preise für OpenAI GPT4-o1 eingetragen; dort standen zunächst die niedrigeren Preise für das Nicht-Reasoning-Modell 4-o, Modellgröße für DeepSeek korrigiert
Nachtrag: Börsenmassaker macht neugierig…
…dass sich gestern 600 Milliarden Euro Börsenwert einfach in Rauch aufgelöst haben (Tagesschau), weil die Investoren denken: Die OpenAI-Wette auf immer größere KI-Computer geht vielleicht nicht auf — das macht offensichtlich neugierig: Die Deepseek-App ist im Apple-Store zum Ende des Januars 2025 auf Platz 1.
Nerdanhang: DeepSeek systematisch testen!
Ich kann es nicht oft genug betonen, wie sehr bei generativer KI der Zufall eine Rolle spielt. Deshalb sollte man Dinge nicht nur einmal probieren, sondern zehnmal, hundertmal, bevor man eine endgültige Aussage über eine KI trifft.
Das habe ich diesmal nicht getan, aber wenigstens kann ich die Werkzeuge präsentieren, mit denen man es tun kann:
- Basis ist die No-Code-Test-Oberfläche Chainforge, wie ich sie zuletzt zum Rollen-Prompt-Messen benutzt habe. Auf dem eigenen Rechner installieren, entweder direkt oder in einem Container.
- Chainforge lässt sich einfach erweitern: Auf das Zahnrädchen für die Einstellungen klicken und das Tab „Custom Providers“ wählen.
- Jetzt brauchen wir ein Erweiterungs-Skript, um DeepSeek einzubauen. Sebastian Mondial hat eine solche Erweiterung geschrieben. Die Datei deepseek-chainforge-provider.py herunterladen und per „Drag & Drop“ in Chainforge einbauen.
- Einen API-Key von Deepseek braucht man natürlich auch noch – der muss bei den Modell-Parametern im Chainforge-Prompt-Node eingetragen werden. Man hat die Wahl zwischen dem herkömmlichen DeepSeek (Chat) und dem R1-Modell (Reasoning).
Schreibe einen Kommentar