

Wie zivilisiert man einen KI-Bildgenerator? Teil 2 von 3 mit der Frage: Ist die Frage nicht inzwischen überflüssig geworden? Tatsächlich geben uns neue KI-Modelle ungeahnte Kontrolle – und sind doch unterlegen, wenn es um guten Stil geht.
Im ersten Teil meiner kleinen Serie ging es um KI, die man auf eine bestimmte Person nachtrainiert, und um vor allem Midjourneys Fähigkeit, existierende Bilder als Vorbild für neue zu nutzen. Heute schauen wir uns daran an, wie sich die Technik weiterentwickelt hat – und werden sehen, dass die neuen Bild-Modelle von Google und OpenAI weiter Schwächen haben, wenn es um reproduzierbaren Stil geht.
Großer Sprung vorwärts: ChatGPTs 4o-image und Googles Nano Banana
Diffusions-Bildgeneratoren liefern Bilder von immer besserer Qualität, haben aber eine entscheidende Schwäche: Sie haben kein Verständnis der Welt und der Dinge in ihnen. Sie kombinieren die Begriffe, die sie darstellen wollen, oft ohne die Logik, die wir aus der wirklichen Welt kennen: Ein Roboter, der ein Einhorn malt? Wurde in der Regel ein malendes Roboter-Einhorn.
Im Mai 2025 baute OpenAI dann ein neues KI-Bildmodell in ChatGPT ein: Das Bildmodell war in ein multimodales Sprachmodell hineingebacken – und konnte deshalb die innere Logik von Prompts besser erfassen und Bilder direkt als Eingabe nutzen. Und im August warf Google “Nano Banana” auf den Markt, das ebenso die Eigenschaften eines Bilderzeugers und einer Sprach-KI verbindet.
Diese hybriden Modelle sind an diesen Punkten im Vorteil:
- Sie haben ein besseres Konzept davon, wie Dinge zusammengehören: “Male einen Roboter, der ein Einhorn malt”, stellt kein Problem für sie dar.
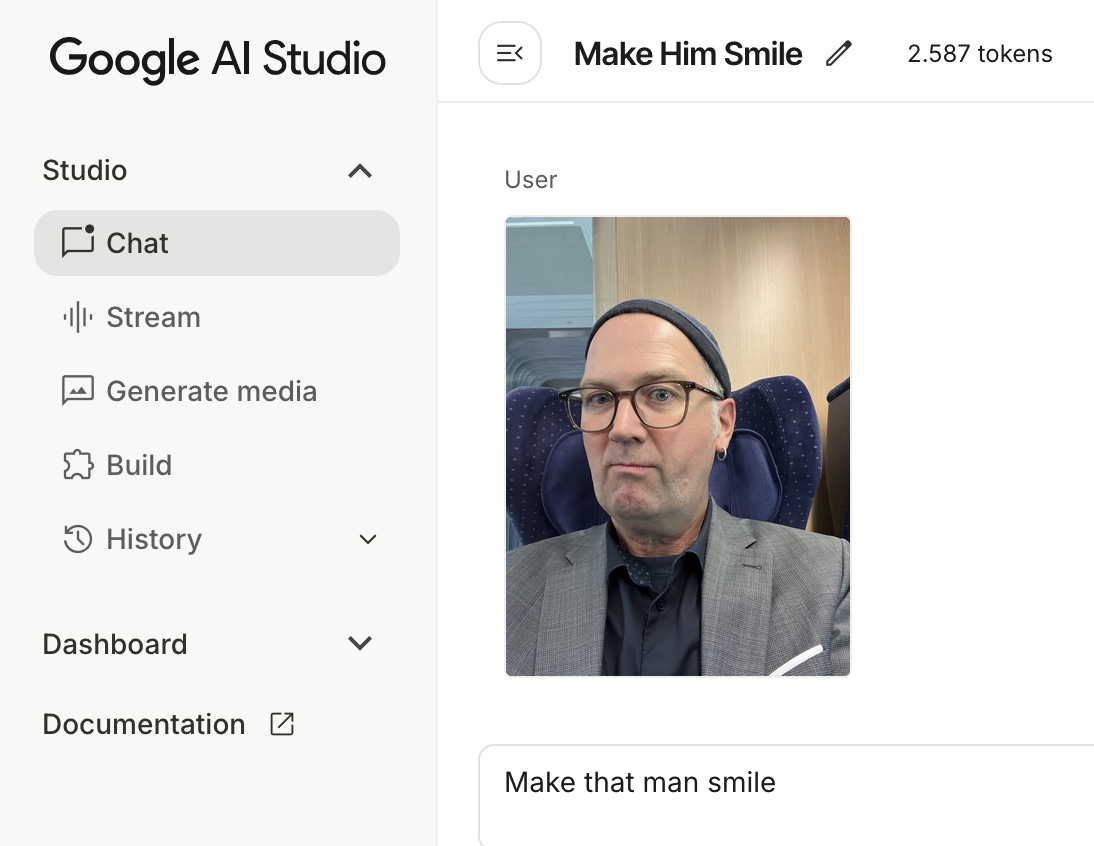
- Man kann ihnen sagen, wie sie Bilder verändern sollen: “Zieh dieser Person einen grünen Pullunder an” – für diese Modelle kein Problem. (Mehr dazu unterm Punkt: Iterativ prompten…)
- Sie können Informationen aus anderen Bildern übertragen – und so zum Beispiel ein und dieselbe Person in unterschiedlichen Bildern darstellen. Oder die Bildkomposition übernehmen.
Der wesentliche Unterschied zwischen den beiden KI-Modellen: Das Google-Modell ist schnell. 8-10 Sekunden dauert es, bis eine neue Fassung des Bildes erstellt ist; bei ChatGPT kann die Erzeugung schon mal eine Minute dauern. Ich vermute, dass das proportional zum Energieverbrauch der Modelle ist; das Google-Modell scheint deutlich effizienter zu arbeiten. Aber mehr als Vermutungen dazu haben wir nicht.
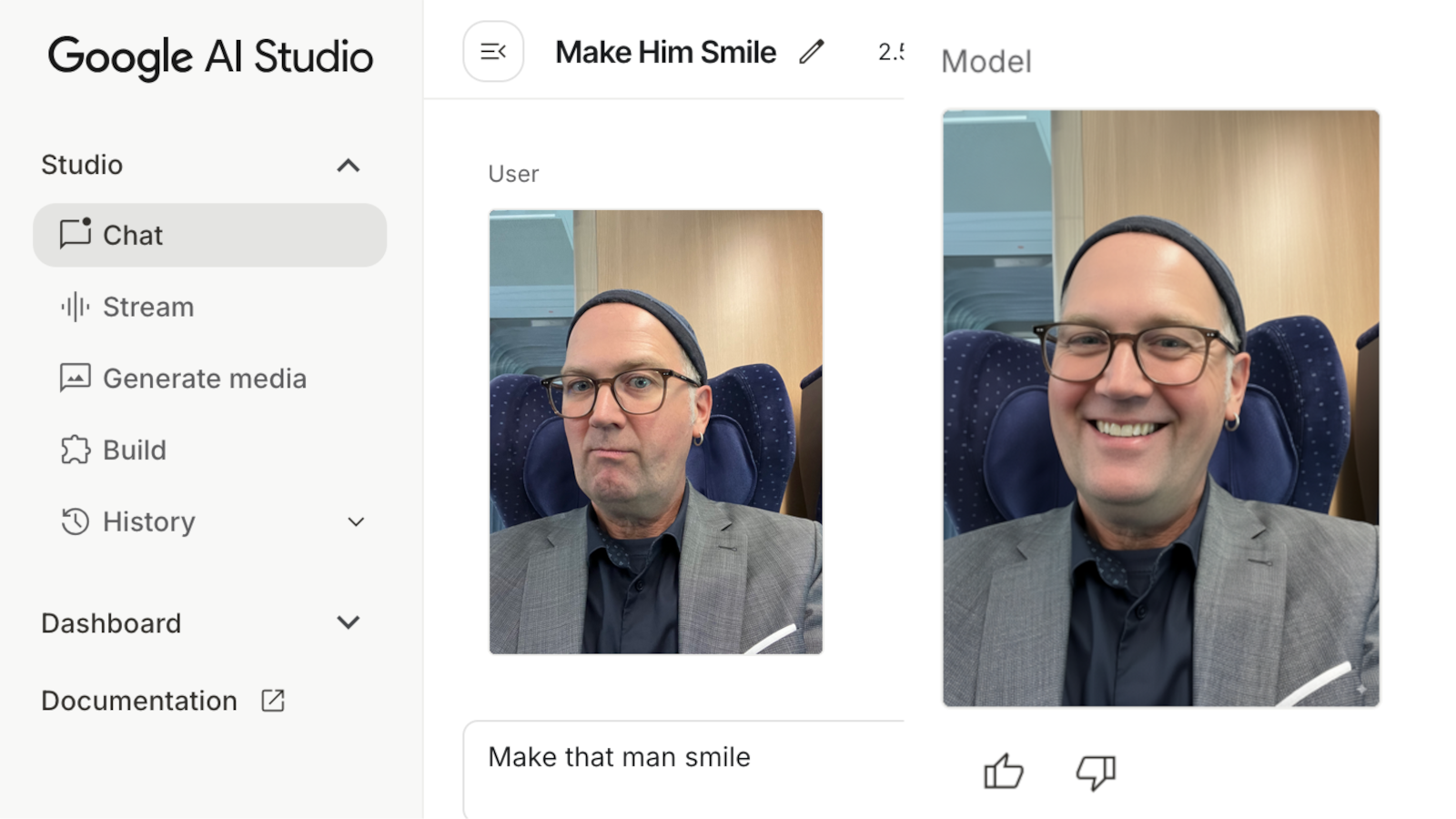
Das hat das Zeug, Bildbearbeitung völlig neu zu definieren. Google gibt sich erkennbar alle Mühe, das neue Modell auf möglichst viele Geräte zu bringen; selbst im Photoshop soll es bereits als Tool verfügbar sein.
Lokale Variante: Open-Weights-Modell aus China
Es gibt auch ein leistungsfähiges Hybridmodelle von Alibaba: Qwen-Image-Edit. Es wird als „Open Weights“-Modell angeboten, also zum Herunterladen.
Wie bei den Sprachmodellen kann es durchaus eine gute Idee sein, KI-Bildmodelle auf dem eigenen Rechner auszuführen. Bei den KI-Bild-Bastlern hat sich 🌐 Comfy UI durchgesetzt; ein Open-Source-Projekt, bei dem man die Funktionsmodule der Modelle miteinander verschalten kann wie Elektronik in einem Schaltschrank. Comfy UI setzt allerdings eine Menge voraus: an Willen, sich in die Innereien der KI-Bildgenerierung einzuarbeiten, an Bastelfreude. Leistungsfähige Hardware braucht man – das 🌐 ComfyU-Tutorial für Qwen setzt voraus, dass man genug Grafikspeicher für die 20 Gigabyte des angepassten Modells hat. Und Geduld.
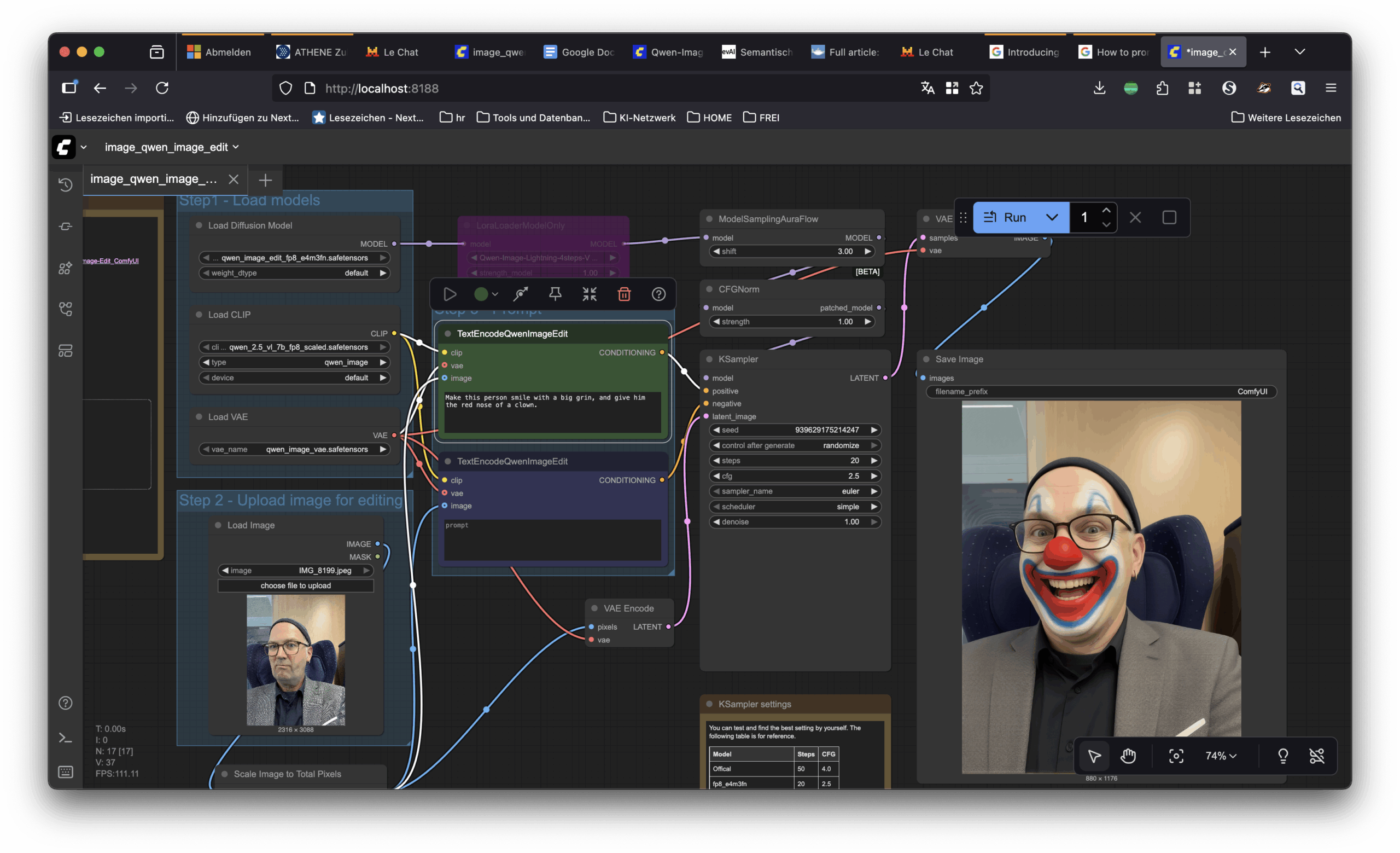
Das kleine Experiment oben brauchte fast acht Stunden, bis es durchgelaufen war – für ein Bild. Dabei nutzte das Modell allerdings nur die CPU und nicht den X-fach schnelleren Grafikprozessor; es gibt zwar auch Module, die für die Mac-GPU optimiert sind, aber so tief wollte ich für das Experiment nicht einsteigen. Halten wir fest, dass mein Standard-Tipp für lokale KI – „nimm besser nen Mac“ – diesmal nur eingeschränkt gilt.
Arbeiten mit Referenzbildern, Nano Banana Style
Die große Stärke von Generatoren wie Googles neuem Modell ist, dass sie auch gut mit Bildern als Input umgehen können – und weil sie ein semantisches Verständnis mitbringen, was auf den Bildern zu sehen ist, können sie auch einzelne Elemente von einem Bild in ein anderes transportieren. Angelehnt an einem Beispiel, das Google in seinem 🌐 Nano-Banana-Prompt-Ratgeber vorschlägt, versuche ich mich an einem simulierten Modelshooting: bekomme ich ein schickes Bild von mir im Anzug von Sam Spade vor einer Science-Fiction-Kulisse?


Das Ergebnis überzeugt mich in diesem Einzelfall nicht völlig, aber ich würde wieder vermuten: Zufall; Pech gehabt. Im Prinzip ist das Modell dazu in der Lage, Elemente aus mehreren Bildern glaubhaft zu kombinieren – das ersetzt mal den Grafiker, mal das Modelshooting.
Stil bleibt ein Problem
Personen kann man sehr gut aus einem Bild in ein anderes übertragen. Was nicht so gut funktioniert, sind Stile, und das ist prinzipbedingt: Ein Stil ist etwas, das sich oft erst in der Gesamtschau mehrerer Bilder ergibt. Google jedenfalls klebt merklich zu sehr an Bildmotiven und -Komposition, um wirklich das leisten zu können, was wir uns eigentlich wünschen: beliebige Motive nach einem Bild-Muster zu gestalten.
Wer mithelfen will, nach Aufgaben zu suchen, an denen selbst Nano Banana scheitert: hier habe ich ein paar Challenges versammelt; weitere gern in die Kommentare. Wie man es aber hinbekommt, dass generierte Bildmotive einen Stil haben, eine wiedererkennbare Handschrift: darum geht’s im dritten Teil der Serie Ende der Woche. Mit einem schmutzigen Hack für die neuen Hybrid-Modelle.
Auch lesenswert:
- OpenAI und die Urheberrechte: Ist KI trainieren wie Radkappen klauen?
- Stilübung (3): Bewahr dir meinen Stil! Wie man ein KI-Bild mit einer Handschrift versieht
- Stilübung (1): Wie kann ein Bildgenerator reproduzierbare Ergebnisse liefern?
Schreibe einen Kommentar