


Teil 3 von 3 zu KI-Bildgestaltung: Dass KI jetzt auch Bilder retuschieren kann, ist toll. (Außer für die Grafiker.) Häufiger wird man aber an der Bebilderung eines Textes arbeiten und darüber nachdenken, wie eine Bildidee in einen Stil zu bringen ist.
Der Raum übertraf die meisten Konferenzräume, denn einmal war von allem genug da: Kaffee, Brezeln, Motivation. Zwei Dutzend Kolleginnen und Kolleginnen sahen mich erwartungsvoll an. Ich durfte mit ihnen erkunden, was der beste Weg ist, eine wiedererkennbare Handschrift zu erzeugen; einen Stil, der ins Auge springt, sich aber auch an verschiedenste Bildmotive anpasst.
Wo wir uns getroffen haben und bei wem, werde ich nicht verraten, aber wann: es war Anfang 2025, also noch vor der Veröffentlichung der Bildgeneratoren, die zuletzt im zweiten Teil das Thema waren. Trotzdem behaupte ich: Was wir damals herausgefunden haben, hat weiter Bestand; schließlich ist ein wiedererkennbarer Stil eine der wenigen Schwächen der Hybrid-Modelle wie Google Nano Banana, ChatGPT 4o-image und Qwen-Image-Edit.
Die Möglichkeiten:
- Prompt-Schablonen: Ausgefeilte Stilbeschreibungen
- Prompting mit Referenzbildern
- Feintuning: Ein mit Beispielbildern nachtrainiertes KI-Bildmodell
- Moodboards, die Midjourney-Variante des Feintunings.
1. Prompt bedient: Magische Worte für den richtigen Stil?
Kann man einen durchgängigen Stil in die richtigen magischen Worte fassen? Zumindest kann man einem Bildgenerator genauer sagen, was man sehen will. Allgemeine Tipps für bessere Bild-Ergebnisse:
- Beschreibe genau, was du willst. Midjourney rät, an Thema, Medium (Hochglanzfotografie? Malerei? Sofortbild?), Umgebung, Licht, Farbe Stimmung und Bildkomposition zu denken.
- Beschäftige dich mit Schlüsselwörtern für Stile. Das können neben den Namen von Künstlern (“Edward Hopper”) und einfachen Begriffen wie “photorealistic”, “digital art”, “crayon”, “stock photography”, “cinematic” auch etwas obskurere technische Begriffe sein: “anaglyphic”, “Fujicolor Superia X-TRA 400”, “8k”. Ein paar Vorschläge für Schlüsselbegriffe auf midjourney.com, ansonsten der Verweis auf das Midjourney-Prompting-Tool.
- Beschreibe auch, was du nicht willst. “Negative Prompts” sind möglich, sowohl bei ChatGPT und Co. wie auch bei bei den konventionelleren Bildgeneratoren wie Midjourney, die dafür Schlüsselwörter wie –no nutzen.
An dieser Stelle mal ein Lob für einen Bildgenerator, der sonst nicht viel Liebe abkriegt: Firefly von Adobe. Die Begeisterung der Grafikprofis für diese KI, die sie mit dem Photoshop aufgedrängt bekommen, ist merklich abgekühlt, seit ihre Nutzung Credits kostet. Aber Firefly macht vieles richtig; man merkt, dass Adobe sich viele Gedanken darüber gemacht hat, wie man gutes Prompten erleichtern kann.
Auf der Firefly-Webseite finden sich dann auch jede Menge Auswahl-Möglichkeiten, um das generierte Bild in eine bestimmte Richtung zu drehen: für Farbgebung, künstlerische Ausrichtung, Anmutungen, vieles mehr. Wenn man sie anklickt, werden auch nur Schlüsselwörter in den Prompt geschrieben, aber das ist gut gemacht und effektiv. Bis zu einem gewissen Grad.
Ich sag’s offen: Die Profis bei unserem Workshop waren sich sehr schnell einig, dass Prompt-Schablonen nicht die Lösung sind.
2. Gute Referenzen? Stil-Musterbilder
Wie erwähnt bin ich der Ansicht, dass die Hybrid-Modelle, allen voran Google Nano Banana, bei der Übernahme von Stilen überraschend schwach sind. Allerdings, wenn man die Idee einer Prompt-Schablone mit der Idee eines Referenzbilds kombiniert und die Stärken von Sprachmodellen ausnutzt, dann… voilá: der JSON-Trick. Er soll am Ende Thema sein.
Einige Bildgeneratoren bieten die Möglichkeit, ein Bild als Vorbild anzugeben und dessen Stil auf ein neues Bild übertragen zu lassen. Neben Midjourney – der Überblick über die verschiedenen Möglichkeiten, mit Bild zu prompten, findet sich hier – ist das wiederum Firefly. Dort kann ich ein Bild mit Stil-Referenz entweder aus einer Galerie auswählen oder selbst hochladen, und ja, dass funktioniert ebenfalls ganz gut.

James Cagney als Prohibitions-Brutalo Cody Jarrett als Vorbild, „Ein Kleinkind auf dem Dreirad mit einer Wasserpistole“ als Prompt. (Spielzeugpistolen hat der Content-Filter verhindert.)
Aber auch mit Bildreferenz kamen wir im Workshop nicht zu Lösungen, die die Profis durchgängig zufriedengestellt haben. Die Schwankungen waren zu groß, der Stil nicht deutlich genug wiedererkennbar: Aus einem Muster lässt sich schwer ein durchgängiger Stil ableiten.
3. Schrauberlösung: Feingetunte KI-Modelle
Im Blogpost über die Hybrid-Modelle hatte ich Comfy UI erwähnt, gewissermaßen die Schrauberwerkstatt für den KI-Bildbastler. Die Comfy-UI-Oberfläche erlaubt, KI-Bildgenerator-Modelle auf eigenen Rechnern zum Laufen zu bringen. Das ist unbestritten nützlich, aber die wahre Magie liegt in den Möglichkeiten, die das bietet.
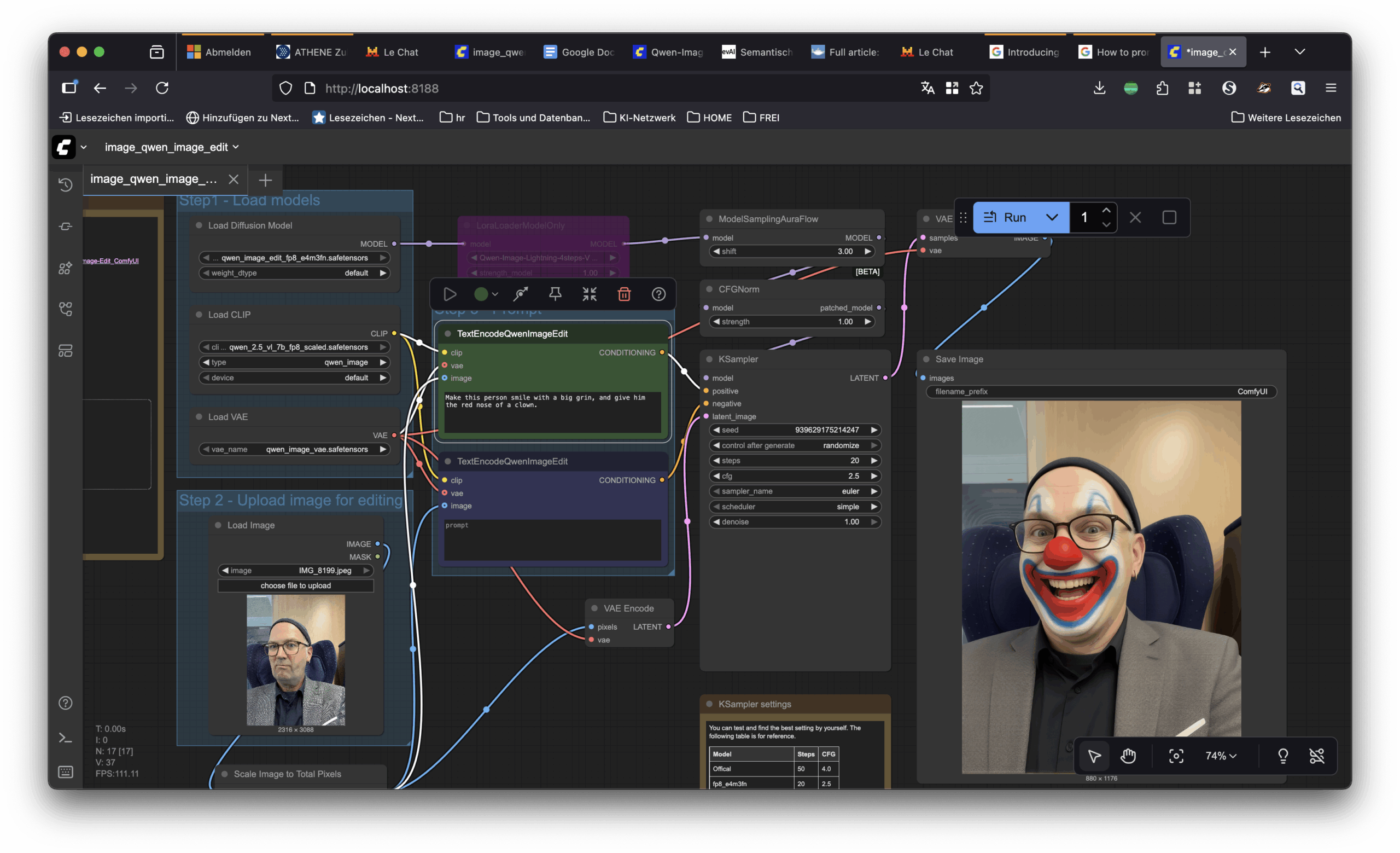
Die Schrauberszene rund um Comfy UI nutzt die komplexe Technik vor allem deshalb, weil sie enorme Flexibilität ermöglicht, zum Beispiel durch so genannte LORAs, kleine Dateien, die das Modell an weitere Trainingsvorgaben anpassen. „Mein“ Flux, das mich darstellen kann, arbeitet hinter den Kulissen mit einem LORA; andere LORAs ermöglichen Manga-Stil, Polaroid-Optik, Röntgenbilder… (🌐 Flux Lora)
Klingt beeindruckend, aber im Stil-Workshop fielen sie glatt durch: Der Versuch, analog zu dem personalisierten Bildgenerator aus Folge 1 eine angepasste Flux-Variante mit Stil zu bauen, scheiterte. Vielleicht lag es an den Trainingsbildern, vielleicht daran, dass man länger hätte mit Comfy UI herumbasteln müssen: es kam einfach nichts Verwertbares heraus. Ich glaube, dass man das generalisieren kann: LORAs sind keine besonders praxisnahe Lösung. Sie benötigen zu viel Feinarbeit und zu viele Versuche, bis sie Bilder genau im gewünschten Stil produzieren.
Change my view.
4. Moodboards: Feintuning á la Midjourney
Wie zeigt man einer Profi-Grafikerin, wie man sich das Design vorstellt? Durch ein Album von Bildern, Mustern, Vorbildern: durch ein Moodboard. Midjourney hat sich nicht nur das Wort genommen, sondern auch das Konzept: Als Anwender kann man mit einem Dutzend oder mehr Referenzbilder vorgeben, wie man sich das Ergebnis stilistisch wünscht.
Technisch ist das nichts anderes als ein Feintuning, aber der Unterschied ist spürbar: Die 🌐 Midjourney-Moodboards liefertern im Workshop deutlich bessere Ergebnisse als das Herumgemurkse mit LORAs, und das sofort. Und das ist kein Zufall: Moodboards sind ein Profi-Tool, das es in dieser Form meines Wissens nach bei keinem anderen Anbieter gibt. Und auf das sich der Workshop am Ende ziemlich einhellig verständigte.
Auch das Titelbild für diesen Post ist mit einem Moodboard entstanden, das ich mit meinen Lieblings-Beitragsbildern von janeggers.tech gefüttert habe. Es sollte aber klar geworden sein, dass die Moodboards vielleicht einzigartig sind, aber nicht alternativlos: Auch mit den anderen Methoden kann ich gute Ergebnisse und einen durchgängigen Stil erreichen. Es kostet nur etwas mehr Mühe und deutlich mehr Versuche.
Und jetzt: Der JSON-Trick.
Wenn man in ChatGPT den Stil eines generierten Bildes auf ein anderes übertragen will, muss man nicht unbedingt das generierte Bild in einen neuen Chat laden. Es reicht, folgende Anweisung zu geben:
Erzeuge ein JSON-Profil aus dem Bild.
ChatGPT erzeugt dann (meist!) eine kleine Datei im JSON-Format – JSON ist ein Behälter für Steuerdaten, den Programmierer lieben, weil er dafür sorgt, dass ihre Programme die Einstellungen an der richtigen Stelle und mit den richtigen Stelle finden. Und in diese JSON-Datei speichert ChatGPT die Informationen über das erzeugte Bild. Man kann also über den JSON-Trick perfekte Stil-Schablonen erstellen, wie beispielsweise dieser Reddit-User schwärmt.

Machen wir das Experiment – und lassen uns zu dem obigen Bild eine JSON-Datei erzeugen. Und wenn man diese Datei in einen neuen Chat lädt und ChatGPT anweist: “Ändere die JSON-Datei so, dass sie von einem Papagei handelt statt von einem Leoparden, und dann erzeuge ein Bild daraus” – oder, Nerd-Variante: einfach in der JSON-Datei das Wort „Leopard“ durch „Papagei“ ersetzt, bekommt man die gewünschte Variante!
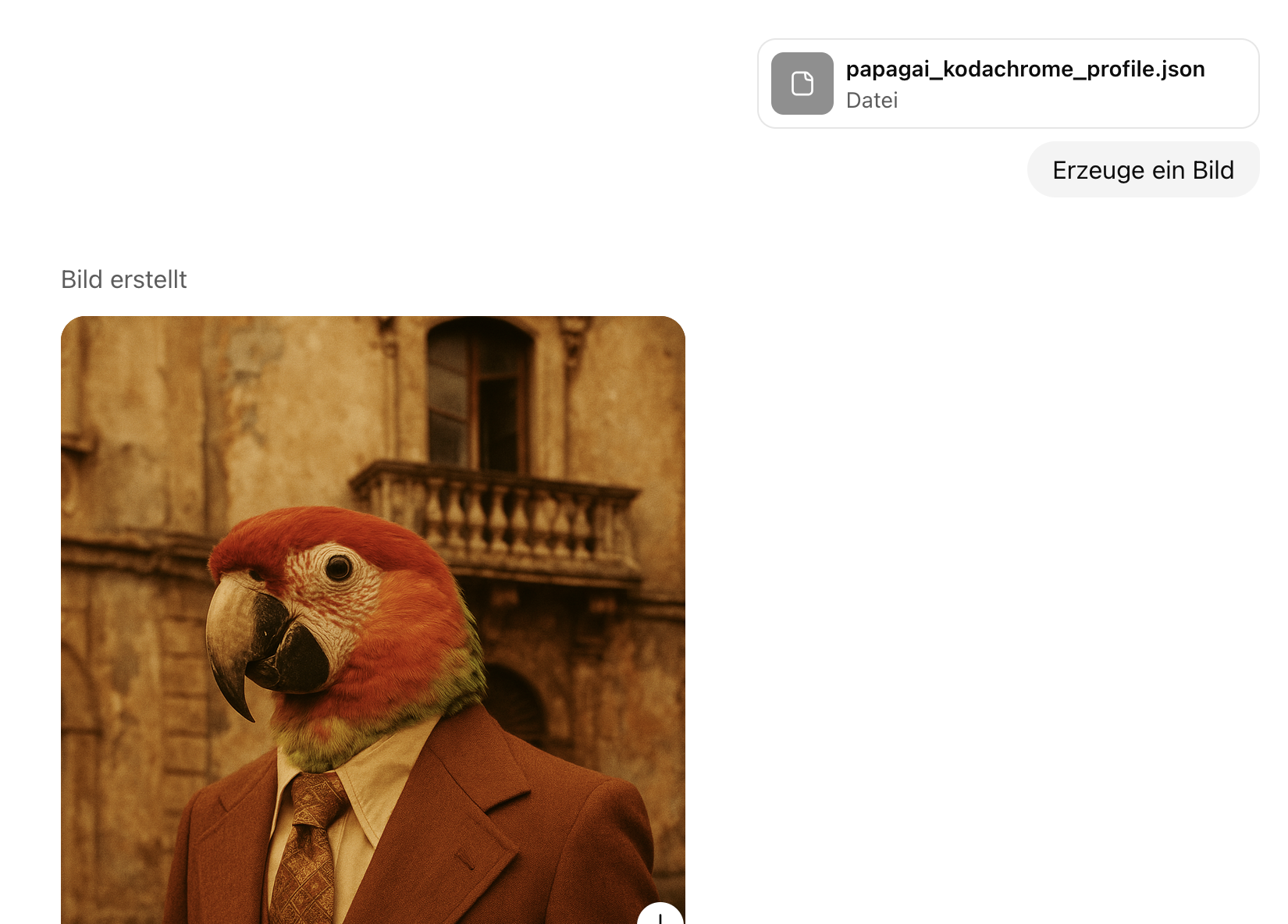
…bis zu einem gewissen Grad: Wer genau hinschaut: Der Palazzo ist anders, das Krawattenmuster auch. Der Stil ist zwar bewahrt worden, aber die Übertragung funktioniert nicht perfekt.
Und so funktioniert der JSON-Trick:
Das zeigt uns, was die JSON-Datei eigentlich tut: Sie beschreibt nur sehr genau, was in dem Ausgangsbild zu sehen ist – und das in einer Form, die ein Sprachmodell wie ChatGPT gut verarbeiten kann.
Tatsächlich denke ich, dass der Trick keine geheimen Zugänge, keine Steuercodes nutzt – sondern nur darauf basiert, dass Sprachmodelle sehr gut auf strukturierte Daten wie JSON reagieren. Technisch tut der Trick also nichts anderes, als das Sprachmodell eine sehr präzise, gut nutzbare Bildbeschreibung verfassen zu lassen.
Das ändert nichts daran, das er richtig gut ist!

Auch das Titelbild dieses Posts ist mit ChatGPT erzeugt und verändert – das erste Papageienbild mit einem JSON des Ringers, das zweite mit einem simplen: „Kann dieser Papagei bitte ein blaues Ringerkostüm tragen?“ Das geht nämlich auch, auch wenn es viel, viel, viel länger dauert als bei Google.
Geht sogar mit Nano Banana!
Auch Googles neues Modell baut letztlich ja auf einem Sprachmodell auf, und kann deshalb nicht nur einst schwierige Kompositionsaufgaben bewältigen: 
Zuerst weigert es sich zwar, fragt noch nach, was es eigentlich in diesem JSON beschreiben soll, gibt dann aber doch brav eine Bildbeschreibung als JSON-Datei aus. Gegenprobe: Geht’s bei ChatGPT? – Ja, tut’s. Und mit Nano Banana selbst auch.
Hat die KI gut gepromptet.



Auch lesenswert:
- Stilübung (2): Hybrid-Modelle für die volle Bildkontrolle
- OpenAI und die Urheberrechte: Ist KI trainieren wie Radkappen klauen?
- Prompting-Formeln sind Bullshit. Hier ist meine.
Schreibe einen Kommentar