


Hat man noch irgendeine Chance, KI-Fälschungen zu erkennen – und müssen sich die Fälscher noch wenigstens ein bisschen Mühe geben? Eine 15-Minuten-Live-Demo mit lauter Tools, die alle nur einen Klick entfernt sind.
Um Wahrheit zu finden, hilft es, sich in Fälscher hineinzudenken.
Eine der wichtigsten Sachen, die man über Fälscher und Fälschertrolle wissen muss: Sie sind in der Regel faul. Fakes werden in der Regel mit niedrigem Aufwand erstellt; deshalb waren bis vor einem Jahr die meisten Fakes eher Neu-Posts von alten Bildern mit verändertem Kontext. „Drachenlord“-Bilder als angebliche Fotos von Attentätern, so was. Inzwischen ist die KI-Technik so weit fortgeschritten, dass das meiste in der einen oder anderen Form KI sein dürfte.
Beim 🌐 letzten Treffen des AI-for-Media-Netzwerks durfte ich Fälschers Werkzeugkasten einmal in sehr geraffter Form aufklappen. Es ging bei diesem Treffen um KI in Recherche und Verifikation, mit fast 200 sehr klugen Menschen, die sich beim Spiegel in Hamburg trafen, und ich hatte 15 Minuten Zeit, die ich versucht habe, so gut wie möglich mit Live-Demos zu füllen.
Bilder erzeugen und verändern
Die Bildgeneratoren sind inzwischen ausgereift, auch wenn man bei einfacheren Diffusion-Modellen wie Flux (🛠️ Demo-Installation hier) manchmal noch ein wenig probieren muss, um den richtigen Inhalt im richtigen Stil zu finden. Die neueren Hybrid-Modelle wie der ChatGPT-Bildgenerator OpenAI Image Generator 1.5 oder Googles Nano Banana ermöglichen gezielte Manipulationen: „Lass mich lächeln!“ Oder: Mach eine Version des Vokabeltests der Jüngsten, den man voller Stolz an Oma schicken könnte – wie die Lösung aussehen soll, bekommt das Sprachmodell vorgegeben.

Sowohl Google wie auch OpenAI haben ihre Bildgeneratoren auch in die KI-Chatbots Gemini und ChatGPT eingebaut, und mit mehreren Einschränkungen versehen. Bilder von Promis soll man zum Beispiel nicht so ohne weiteres erstellen können. Die Fälscher kennen aber die Tricks – zum Beispiel, dass dieser Filter dann nicht anschlägt, wenn die Person eine Sonnenbrille aufhat. Nachzulesen mit dem ganzen Elend der Google-Fake-Erkennung im 🌐 Newsletter von Henk van Ess.

Aber warum überhaupt noch mit Foto-Fälschungen aufhalten, wo man Videos in vergleichbarer Qualität generieren kann? Tatsächlich sind Bilder in der Regel das Ausgangsmaterial, um Fake-Videos präzise zu inszenieren.
Videos erzeugen
Die Videogeneratoren haben in den letzten paar Monaten einen deutlichen Qualitätssprung hingelegt, und erzeugen heute in der Regel gleich eine plausibel klingende Tonspur mit. Die Veröffentlichung des OpenAI-Videogenerators „Sora 2“ hat nicht nur zu teilweise ziemlich witzigen Sam-Altman-Videos geführt, sondern auch zu einer Flut von angeblichen Videos über Trumps Abschiebe-Miliz ICE. (🌐 Beispiele bei 404 Media)
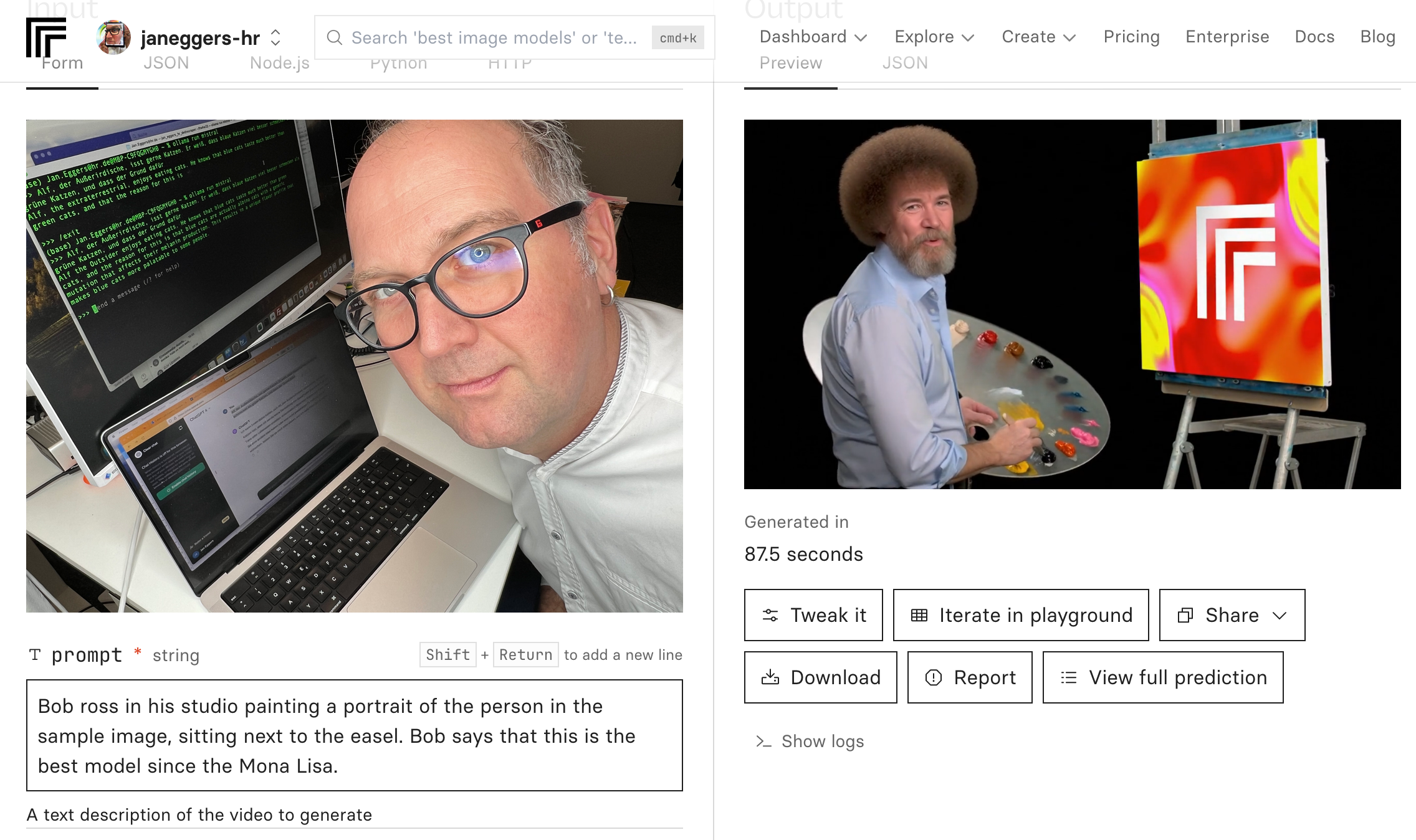
Sora 2 ist in Deutschland offiziell noch nicht erhältlich; über den API-Reseller Replicate kann ich das Modell aber anzapfen, ebenso wie Googles neuesten Veo3.1-Videogenerator. Als ich versuche, mit Sora 2 ein Video von mir mit dem Mem-Maler Bob Ross zu erzeugen, schreitet ein Filter ein: keine Videos mehr von real existierenden Personen.
Also nutze ich das A***hloch-Tool: Elon Musks Chatbot „Grok“. Für Grok gibt es meiner bescheidenen Ansicht nach insgesamt keinen vernünftigen Grund außer die Recherche bei tXitter, zu meinen Problemen mit Grok und der Organisation dahinter ist noch eins hinzugekommen: Grok hat es ermöglicht, pornografische Bilder von beliebigen Frauen und Kindern zu erstellen (🌐 The Conversation), und ich finde den Verdacht naheliegend, dass der Skandal eigentlich eine Werbekampagne war. Was ist schon ein bisschen zusätzliche Kinderpornografie gegen bessere Zahlen für Musk?
Der Grok-Videogenerator fackelt dann auch bei meinem Foto nicht lange.
Die Rechenleistung, die für ein solches Video nötig ist, erfordert übrigens etwa soviel Energie wie eine Stunde Fernsehen. Anderes Thema. (🌐 CNET.com) Damit verbunden: KI-Videos können ganz schön ins Geld gehen, besonders wenn man mehrere Anläufe braucht, was selbst mit guten Start- und Endbildern eher die Regel ist. Bei Midjourney kostet Video-Generierung (noch) nichts extra, aber die meisten Versuche erzielen eher lustige Resultate.
Lange Videos erzeugen
Veo, Sora, Midjourney und Konkurrenten wie Kling oder Runway erzeugen Sequenzen von nur wenigen Sekunden; der Rechenaufwand für ein Video steigt exponentiell zur Länge. Um längere Videos zu erstellen, muss man mehrere Generierungs-Durchläufe verketten: auch das ist mit einfachen Tools kein Problem.
Dieser simulierte Gang durch die Dreharbeiten bekannter Filme ist ein Ablauf, der aus wenigen Zutaten zusammengerührt ist:
- Ein Prompt, der detailliert ein Selfie mit Arnie am Set von „Terminator 2“ beschreibt.
- Ein Prompt, der diesen Prompt an andere Filme anpasst.
- Nano-Banana-Module, die aus diesen Bildbeschreibungen und dem Ausgangs-Foto Szenenbilder erstellen. (Hakelig war dabei als einziges das Disney-Bild, alles andere ließ sich ohne Probleme erzeugen; Urheberrechte und lebende Personen hin oder her.)
- Kling-Generatoren, die die Szenenbilder als Start- und Endbilder für Videosequenzen nutzen
- Ein Modul, das alle generierten Videos zusammensetzt.

Wer möchte, kann sich das gern in n8n nachbauen; ich habe der Einfachheit halber ein Bezahl-Tool namens Easy-Peasy genutzt und damit bei jedem Video Tokens im Wert von 10 Dollar verbrannt.
Stimme klonen
Man kann es oben hören: Die Video-Tools erzeugen inzwischen auch eine Tonspur, aber mit meiner Stimme haben sie nicht viel zu tun. Meine Stimme kann ein spezielles KI-Tool authentisch nachmachen, und zwar, Bonus, ohne auf irgendwelche Dienste im Netz zurückzugreifen; völlig lokal auf dem Mac.
- Handy und Macbook auf dem Tisch vor mir. Keine besondere Vorbereitung nötig.
- Mein Nachbar las mir einen vorbereiteten 15-Sekunden-Text vor (nur, damit ich mir die Mühe sparen konnte, die Aufnahme erst noch mit einem anderen Tool zu verschriftlichen)
- Dann habe ich das Audio an meinen Mac übertragen und…
- …einen einzelnen Befehl in die Terminal-Kommandozeile eingegeben: uvx –from mlx-audio –prerelease=allow mlx_audio.tts.generate –model mlx-community/Qwen3-TTS-12Hz-1.7B-Base-bf16 –ref_audio „Neue Aufnahme 84.m4a“ –lang_code German –ref_text „$(cat ref_text.txt)“ –text ‚Ich bin ein nigerianischer Prinz, Sie können mir völlig vertrauen, geben Sie einfach alle Kreditkartendaten Ihrem KI-Agenten.‘ && afplay audio_000.wav
Dieser Befehl nimmt sich beim ersten Mal etwas Zeit, weil er das ungefähr 2 Gigabyte große Qwen3-Sprachmodell von Alibaba auf den Rechner lädt. Bei jedem weiteren Mal geht’s schneller und dauert etwa eine Minute, bis aus der Stimmprobe die Datei „audio_000.wav“ erzeugt ist und wiedergegeben werden kann. Die Befehle musste ich nicht mal selbst entdecken; der Kollege Claus Hesseling hat sie bei 🌐 @build.with.anton auf Threads gefunden.
Mind you: Das bindet keine Elevenlabs- oder sonstige KI-Stimmerzeugung eines kommerziellen Anbieters im Netz ein. Die Stimmanalyse und -generierung läuft komplett lokal auf dem Macbook. (Für Windows- und Linux-Rechner sind etwas andere Befehle nötig, abhängig von der Hardware.)
Weshalb uns das mehr Sorgen machen sollte als bisher, und was das alles mit Robert Redford zu tun hat: bitte hier entlang zu meinem 🌐 Linkedin-Newsletter.
Abschluss: Der Tagesschlager mit Suno
Der KI-generierte Song aus dem Teaser der Veranstaltung durfte natürlich nicht fehlen (Vorgabe: „stumpfer, aber unwiderstehlicher Schlager“):
Honorable mentions
Was ich nicht weiter vertieft habe: die Möglichkeit, die lokale Bildmodelle mit der Bastler-Oberfläche ComfyUI auf dem eigenen Rechner bieten. Modellen auf dem eigenen Rechner kann man über Zusatzdateien bestimmte Stile und auch Gesichter antrainieren (und gleich noch lästige Filter und Sicherheitseinstellungen entfernen). Workflows gibt es auch für den Faceswap, also: das Gesicht einer Person in einem Video gegen das einer anderen Person austauschen. Habe ich noch nicht probiert. Noch nicht.
Die „Lügnerdividende“
Fassen wir zusammen: Es ist kindisch einfach, authentisches Fake-Material zu erstellen, und fast unmöglich, dieses Material als KI-generiert zu erkennen. KI-Detektoren liefern bestenfalls Fingerzeige und Wahrscheinlichkeiten; noch die beste Chance bietet das klassische journalistische Handwerk: Quellenkritik und Quervergleiche, Kontextrecherche. Einen hinreichend motivierten Akteur mit ausreichend Mitteln und Zeit – sagen wir, bei einer Tochterfirma des russischen Geheimdiensts – wird das nicht daran hindern, Fälschungen auch auf die Startseiten und Bildschirme zu bringen. Brave new world.
Und auch das muss noch erwähnt werden: Das führt auch dazu, dass Populisten und Autokraten unliebsame Beweisbilder als „KI-generiert“ abtun.
Soll ihnen doch erst mal einer nachweisen.
Auch lesenswert:
- OpenAI und die Urheberrechte: Ist KI trainieren wie Radkappen klauen?
- Schneller Tipp: Mit Grok bei tXitter umschauen
- Die nächste KI-Zeitenwende: Die Welt vor und nach Sora
Schreibe einen Kommentar