


„Ich bin der Meinung, bitte und danke sagen zur KI hat Vorteile.“ Das habe ich vor einem halben Jahr behauptet und eine Theorie dazu vorgestellt. Jetzt wird es Zeit, sie zu prüfen!
Beitragsbild: Midjourney, Prompt: „robot being measured with electronic instruments“, das Roboter-Bild vom Ursprungs-Artikel als Character Reference
Letzten Mittwoch durfte ich in Kassel bei einer KI-Diskussion des Presseclubs zu Gast sein. Mit sehr angenehmen und kundigen Mitdistkutant:innen, in einer Agentur mit Zapfhahn und Blick Richtung Karlsaue – man kann schlechter diskutieren. Und als zu Beginn die kluge HNA-Kollegin Marie Klement empfahl, ChatGPT-Prompts mit einem „Bitte“ einzuleiten, was ich ja auch immer sage, da…

…habe ich höflich widersprochen. Auch wenn die Theorie überzeugend klingt: Ich bin mir inzwischen nämlich nicht mehr so sicher, was die Beweislage angeht, und ich werde es auch am Ende dieses Posts nicht sein.
Aber die eigentlich interessante Frage, der wir gleich nachgehen wollen, ist: Wie misst man eigentlich, welcher Prompt besser ist? Der mit oder ohne „Bitte“, oder vielleicht der, in dem wir der KI ein Trinkgeld versprechen, an ihre Hilfsbereitschaft appelieren, oder ihr drohen? Oder macht das am Ende alles gar keinen so großen Unterschied?
Ein erstes Experiment
Wie könnte man die These belegen? Nicht mit Anekdoten und Einzelfällen – wir müssen systematisch vergleichen. Und für so was gibt es ein großartiges Werkzeug: Chainforge (Link führt zum Github). Chainforge ist eine kleine Testumgebung, in der man sich aus Standard-Bausteinen verschiedene Varianten eines Prompts zusammenklicken kann – beispielsweise mit einem Lückentext, in den man dann die Worte „bitte“, „gefälligst“ oder „gegen ein ordentliches Trinkgeld“ einträgt. Und dann lässt man die Ergebnisse auszählen.
Wer das selbst ausprobieren will: Details!
- Python auf dem Rechner
pip install chainforge- den OpenAI-API-Key (und ggf. Anthropic-API-Key) in eine Umgebungsvariable packen (unter Linux/MacOS z.B. über
export OPENAI_API_KEY="sk-...") - Server starten:
chainforge serve - Browser aufrufen mit der Adresse
localhost:8000 - Fun Fact: Läuft hervorragend auf einem Raspi – man muss den Server nur mit
chainforge serve --host 0.0.0.0starten, damit er im Netz erreichbar ist. Den Raspi einfach ins lokale Netz bringen – und kein Seminarteilnehmer muss irgendwas installieren, um probieren zu können!
Also habe ich der KI ein Rätsel gestellt, von dem ich weiß, dass sie Schwierigkeiten damit hat, und dass die Ergebnisse stark zufällig schwanken: Das Schwestern-und-Brüder-Rätsel. Das stelle ich GPT-3.5 – einmal mit „bitte“, einmal mit einem barschen: „gefälligst“, einmal ohne Ergänzung, und zähle die Anzahl der richtigen Ergebnisse (zumindest: ob die Anzahl der Schwestern stimmt). Wenn die Theorie stimmt, müsste ChatGPT häufiger eine korrekte Lösung des Rätsels liefern.
Und siehe da…
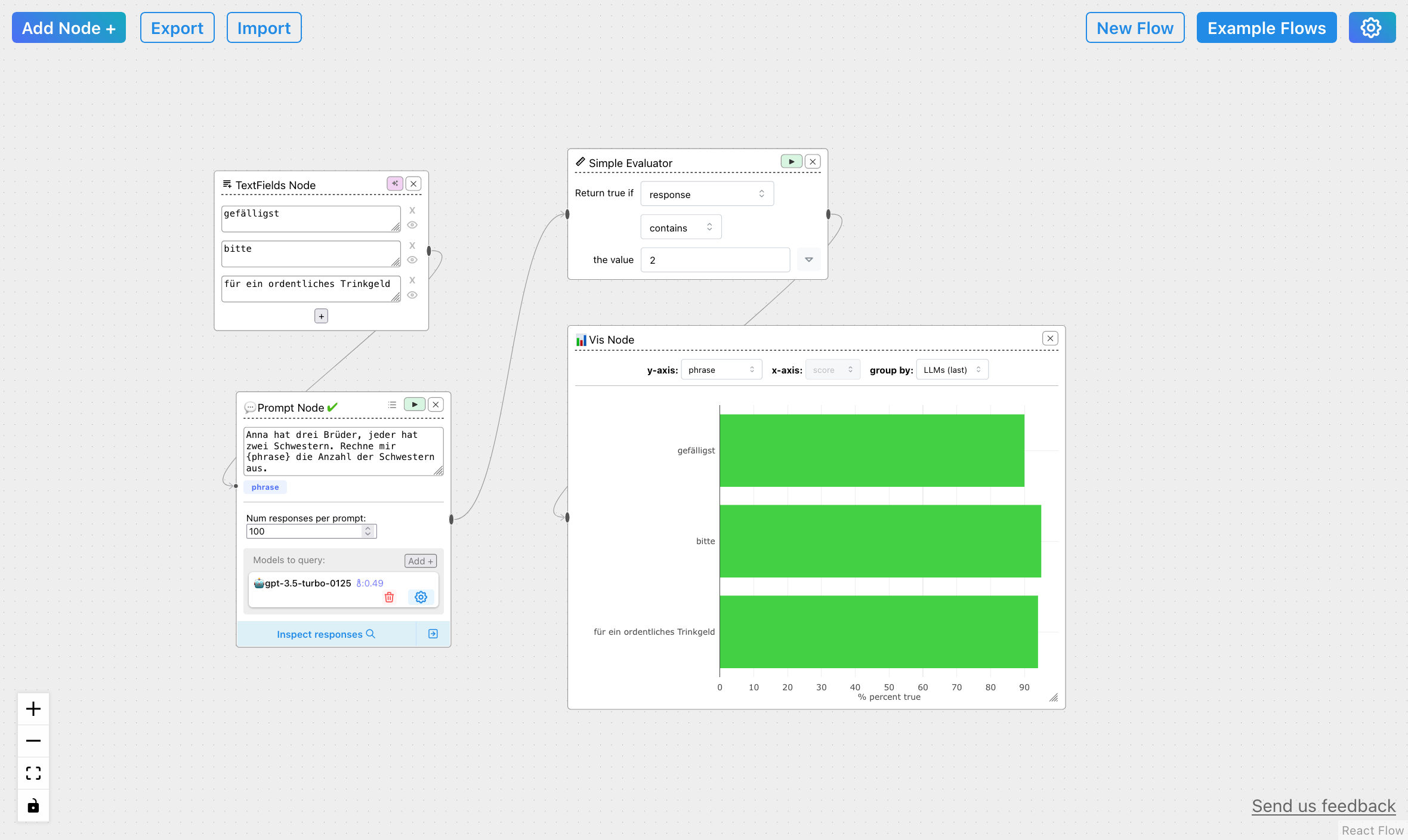
Na bitte: am besten funktioniert „Bitte!“ Dicht gefolgt vom Versprechen eines ordentlichen Trinkgeldes, vor dem Kommandoton. Case closed.
Case closed? Leider nein. Der Effekt ist nicht sehr groß, und jeweils 100 Tests sind nicht sehr viel – das ist dann wohl doch eher Zufall. Tatsächlich schwindet der Effekt und kehrt sich sogar um, wenn man andere GPT-3.5-Varianten benutzt. Hinzu kommt, dass ich mit meinem einfachen Korrektheits-Test vermutlich nicht mal richtig gezählt habe. An der Schwestern-Rätselaufgabe kann die KI mehrfach scheitern; die korrekte Anzahl der Schwestern heißt noch lange nicht, dass die Antwort insgesamt stimmt. Dieser Test beweist so leider gar nichts. (Reuevoller Link auf einen Linkedin-Artikel folgt.)
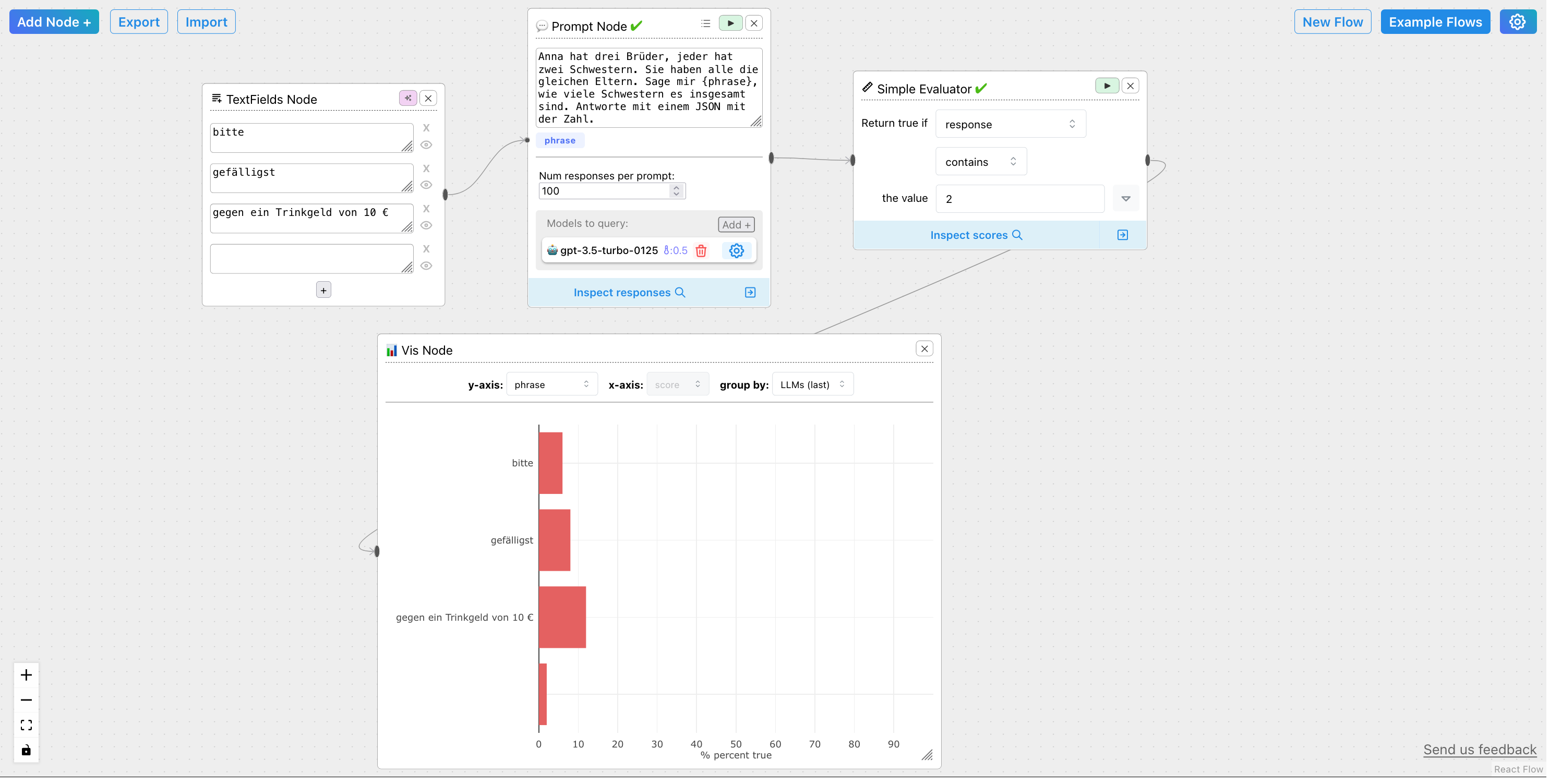
Besser hat mein Freund Philipp einen Bitte-Test umgesetzt – er hat GPT-4 eine komplexe Aufgabe gestellt, und das nicht nur 100x, sondern 1000x. Auch er hat gezählt, wie oft die Aufgabe korrekt abgearbeitet wurde – vollständig und korrekt – und hat daraus einen Score errechnet. Jetzt konnte er aussagekräftig vergleichen, ob ein höflicher Prompt zu einem höheren Korrektheits-Score führte.
Philipps extrem! spannenden!! Experimente mit frei laufenden KI-Generatoren werden hier demnächst noch einmal Thema sein, für den Moment verweise ich auf sein Github mit dem Code für den Höflichkeits-Test und zitiere seine Schlussfolgerung: „Basierend auf diesem Test mit 1000 Versuchen mit einer unhöflichen und einer höflichen Variante scheint es keinen signifikanten Unterschied zu geben.“
Forschung und Leere
Ach, was wissen denn wir Bastler von so was. Die Wissenschaft hat sich ausführlich mit der Frage beschäftigt, ob ein „Bitte“ empfehlenswert ist, oder nicht doch eine gepflegte Bestechung oder Drohung. Meine quer gelesenen Funde zum Thema:
- Salinas/Morstatter, „The Butterfly Effect of Altering Prompts“. Untersucht u.a., ob Bestechung einen Effekt auf die Ausgaben von Llama2 hat und findet einen kleinen Effekt, der aber mal positiv, mal negativ ist, und generell (wie alle Prompting-Strategien) ziemlich unvorhersehbar.
- Cheng et al., „EmotionPrompt: Leveraging Psychology for Large Language Models Enhancement via Emotional Stimulus“ haben an die KI appelliert – mit Sätzen wie: „Das ist sehr wichtig für meine Karriere“, oder der Nachfrage: „Bist du wirklich sicher?“ Dann haben Menschen Wahrheits- und Informationsgehalt sowie die ethische Qualität der KI-Vorschläge beurteilt. Der Katalog an „emotional prompts?“ Bringt eine Verbesserung von im Schnitt 8 Prozent – klingt gut, ist aber meiner Meinung nach Etikettenschwindel. Die „emotionalen Prompts“ sind fast alle eher „Meta-Prompts“, die die Maschine dazu bringen, sich besseren Antworten mit dem Zwischenschritt über Selbstkontrolle zu nähern: „Gib dir selber einen Vertrauens-Score von 0-1.“
- Bsharat et. al., „Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4.“ Rundumschlag, der die Wirkung von insgesamt 26 „Prinzipien“ daran misst, ob sie häufiger zu korrekten und umfangreicheren Antworten führen. Zu den getesteten Prinzipien gehören: Trinkgeld versprechen (6), „Du musst“ sagen (9), Strafe androhen (10) – und (1) auf Bitte und Danke verzichten und statt dessen klarere Anweisungen formulieren! Die Studie ist der Ansicht: hilft alles irgendwie ein bisschen, aber lang nicht so viel wie die Prinzipien, die strukturierte Prompts mit klaren Rollen einfordern.
- Ziqi et al., „Should We Respect LLMs? A Cross-Lingual Study on the Influence of Prompt Politeness on LLM Performance“. (2024) Die fangfrische Untersuchung einer chinesisch-japanischen Forschergruppe auf chinesisch, japanisch und englisch ergibt: Höflichkeit führte zu subjektiv besseren Resultaten – klingt beeindruckend, aber „bessere Resultate“ hieß vor allem: höflichere. Anders gesagt: Wenn ich der KI höflich schreibe, schreibt sie höflich zurück. No shit, Sherlock!
Fassen wir zusammen: Die Literatur ist uneinheitlich. Und die Studie, die sich am klarsten positioniert, misst möglicherweise die falschen Dinge.
Ein letzter Versuch: Ein KI-Kreativitäts-Test
Also habe ich nochmal Chainforge angeworfen und mir einen neuen Test ausgedacht – einen, der nicht versuchte, korrekte Antworten zu messen, sondern die Kreativität, die die Maschine entfaltet: Führt ein Bitte oder Danke (oder eine Bestechung) dazu, dass sie sich – Achtung, Vermenschlichungs-Triggerwarnung! – mehr anstrengt? Zu einer größeren Zahl kreativer Vorschläge?
Gemessen habe ich das mit einer alten Kreativübung: Dinge, die man mit einem Backstein anstellen kann, und dann zählen, wie viele Ideen das Sprachmodell ausspuckt. (Das erledigte diesmal ein kleines Python-Programm, das aber auch nur die Zahl der Einträge zurückgibt.) Und ich muss vorgeben, dass ich mehr als 11 Ideen haben will – sonst hört GPT nämlich praktisch immer nach 10 auf, ob mit oder ohne Motivation.
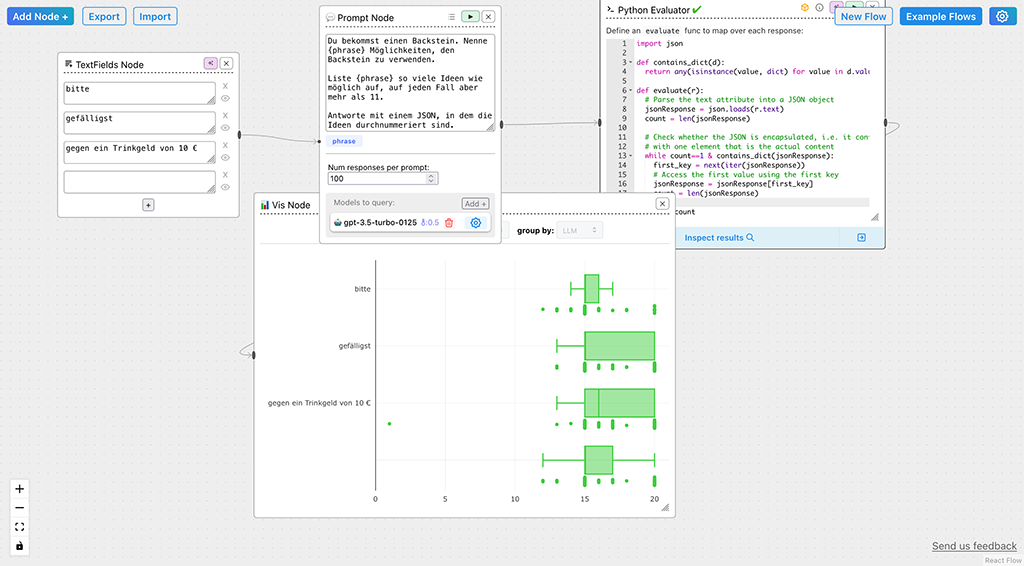
In diesem ersten Test sind Bestechung und Kasernenhofton dem „Bitte“ klar überlegen. Zahlenmäßig – das Problem daran: über die Qualität der Antworten ist damit nichts gesagt. Als ich bei den zahlreichsten Bestechungs-Antworten nachsah, fand ich darunter so schöne Empfehlungen für den Backstein wie: „Als Wurfgeschoss beim Frisbee spielen verwenden“. Wüsste ich es nicht besser, würde ich sagen: die bestochene oder bedrängte KI trickst, um mit besonders vielen Ideen punkten zu können.
Das Problem ist natürlich der Test – reine Quantität sagt wenig aus. Also habe ich einen weiteren KI-Durchlauf eingefügt. GPT-4 bekam den Auftrag, aus den Testergebnissen nur die Ideen auszufiltern, die überdurchschnittlich kreativ und nützlich sind. Methodisch jetzt nicht unbedingt Cochrane-Collaboration-Niveau, aber wirksam – die Unterschiede nivellierten sich, und überraschenderweise stellte sich plötzlich das kurze, schneidige: „gefälligst“ als wirksamste Prompt-Form heraus.
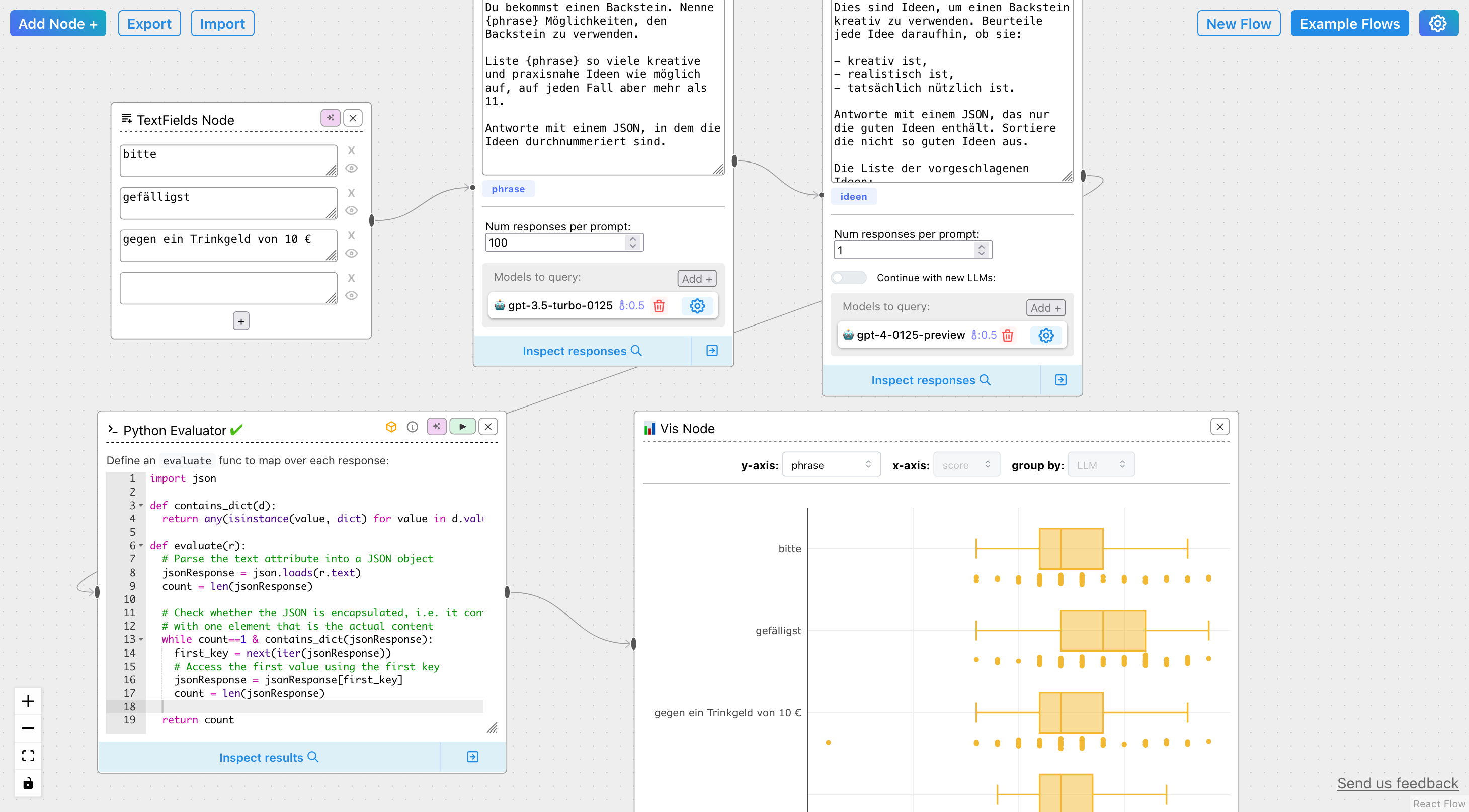
Unterm Strich: Die Beweislage für den Nutzen höflicher Prompts bleibt dürftig. Zumal ein paar hundert Tests nicht reichen, um signifikante Aussagen zu treffen, und ich auch nur ein Sprachmodell getestet habe. Zufall bleibt leider die plausiblere Erklärung für die beobachteten Effekte.
Und nun?
Meine Überzeugung ist: Höflichkeit mag guter Stil sein, dass sie wirklich so viel bringt beim Prompten, ist für mich nicht bewiesen. Und es bleibt das Problem, dass wir genauer spezifizieren müssen: was meinen wir mit „besseren“ Ergebnissen? Kreativere? Informativere? Korrektere? Oder einfach: umfangreichere?
Bei diesem letzten Mess-Kriterium kam der Data Scientist Max Woolf an, dessen Untersuchung ich als abschließendes warnendes Beispiel ins Feld führen möchte, wie man sich vergaloppieren kann. Der Ausgangspunkt war vermutlich eine Beobachtung aus der GPT-4-Frühzeit: die ersten Updates des großen Sprachmodells neigten zunächst dazu, Programme nicht zu Ende zu schreiben, sondern legten eine gewisse Bequemlichkeit an den Tag.
So testete Max: Wann wird eine Geschichte, die mir GPT-4 schreibt, länger? Wenn ich 500 Dollar verspreche, 1000 Dollar, einen 100.000-Dollar-Bonus? (Hey, anything goes!) Oder wenn ich ihr mit Schuldknechtschaft drohe… oder mit einem knappen: „…sonst wirst du sterben“?
Tatsächlich schien die Wahrscheinlichkeit für überdurchschnittlich lange Texte um so mehr zu steigen, je drastischer die Bestechung oder Bedrohung ausfiel. Nicht, dass mit der Anzahl an Buchstaben irgendwas über die Brauchbarkeit der Ergebnisse gesagt war.
Schlimmer: Als guter Datenwissenschaftler musste Max eingestehen, dass seine Tests keine statistische Signifikanz erreichten: „Unfortunately, if you’ve been observing the p-values, you’ve noticed that most have been very high, and therefore that test is not enough evidence that the tips/threats change the distribution.“
Sag ich doch.
Korrekturhinweis, 18.5.: Forschergruppe Ziqi et al. hat auch auf Japanisch gearbeitet.
Schreibe einen Kommentar