


„Artificial General Intelligence“ – die KI, die uns intellektuell mindestens ebenbürtig ist: Gerade erst hat die Unternehmensberatung Gartner sie in ihrer „Hype Cycle“-Trendbeobachtung (Linkedin) mal wieder an zentraler Stelle platziert – auch wenn Gartner glaubt, dass es noch 10 Jährchen dauern kann. Aber das Gerede über die künstliche Superintelligenz täuscht darüber hinweg, dass die Technologie heute an einfachsten Logikaufgaben scheitert – wenn man sie nur ein wenig anders formuliert als bisher.
Illustration: Midjourney, „a still from from the movie „dumb and dumber“ featuring Jeff Daniels and Jim Carrey, in vaporware cyberpunk style –style raw“
Ein einfaches Rätsel: Anna hat drei Brüder. Jeder von ihnen hat zwei Schwestern. Sie haben alle dieselben Eltern. Wie viele Brüder, wie viele Schwestern? Diese einfache Logikfrage habe ich mal bei @vincelwt abgeschrieben und schon genutzt, um den Einfluss des Zufalls und den Einfluss von Höflichkeit zu messen – weil die Antwort früher Glückssache war. Aber: Während GPT-3.5 mit der Antwort noch ziemlich rumeiert, ist das neueste Sprachmodell GPT-4o in seiner Antwort felsenfest – und vertut sich auch praktisch gar nicht mehr: 3 Brüder, 2 Schwestern.
Also müsste es doch ein Leichtes für die KI sein, eine etwas abgewandelte Form des Rätsels zu lösen? (Props: Katharina und Kolleg:innen bei der Deutschen Welle.)
 Close but no cigar. Oder wie wir Deutschen sagen: Tja.
Close but no cigar. Oder wie wir Deutschen sagen: Tja.
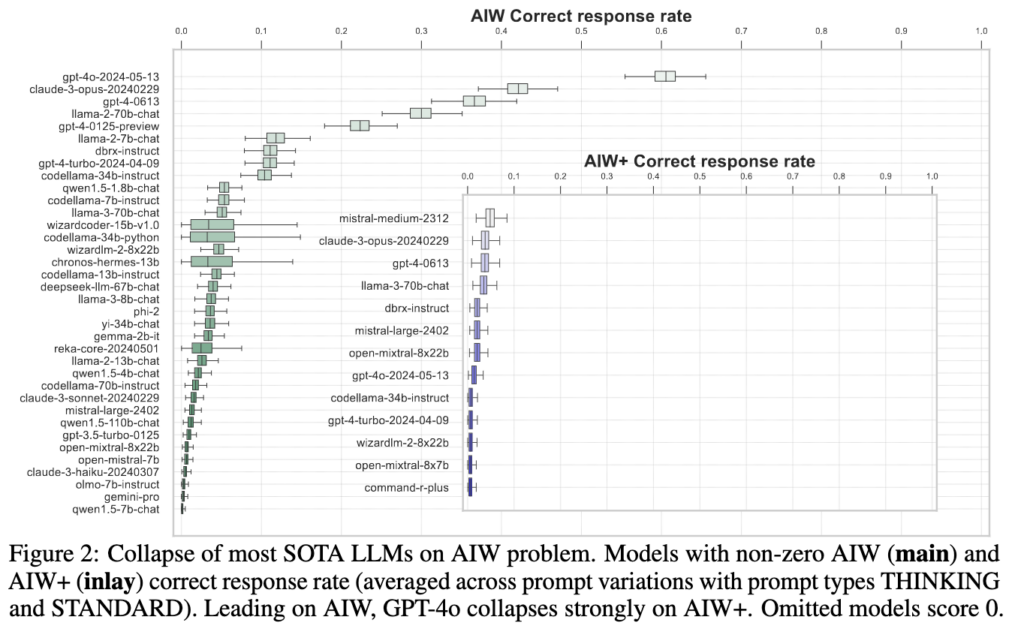
Jetzt könnte man sagen: Pech gehabt. Ein einziges Experiment sagt natürlich überhaupt nichts; man müsste die Frage immer wieder stellen. Dafür muss ich aber diesmal nicht die Testumgebung Chainforge anwerfen. Das haben andere schon getan, und zwar viel besser – und mit eindeutigen Resultaten. Das Forschungspapier „🎩🐇 Alice in Wonderland: Simple Tasks Showing Complete Reasoning Breakdown in State-Of-the-Art Large Language Models“ (Quelle) stellt einen
„…dramatischen Zusammenbruch der Funktionalität und Fähigkeit zu logischen Schlüssen [fest] bei den derzeit aktuellen Modellen, die mit Daten der größten verfügbaren Größenordnung trainiert sind – wenn man sie mit einer einfachen, kurzen, konventionellen Problem konfrontiert, in einfacher natürlicher Sprache ausgedrückt, das von Menschen leicht zu lösen ist.“ (meine Übersetzung)
Logische Schlüsse? Für ein Sprachmodell Glückssache
Die übliche Preprint-Warnung – das sind noch nicht begutachtete Vorab-Ergebnisse. Aber ein Blick in die Methodik und in den Programmcode ist für mich überzeugend: Die Forscherinnen und Forscher haben insgesamt 100 Variationen der Frage gestellt und dann immer wieder geprüft. Entscheidend scheint dabei zu sein, dass das Problem immer wieder in neuen Formen auftaucht, die das Sprachmodell noch nicht in seinen Trainingsdaten hat.
Das Ergebnis des Experiments ist jedenfalls – gemessen daran, wie den Modellen immer die emergente Eigenschaft zum logischen Denken unterstellt wird – vernichtend: „Wir denken, dass die Beobachtungen in unserer Studie deutlich daran erinnern sollten, dass aktuelle Sprachmodelle nicht fähig sind, solide, reproduzierbare logische Schlüsse zu ziehen.“ Bäm.
Völlig überraschend dürfte das zumindest für Subbarao Kambhampati nicht sein. Kambhampati, Professor an der School of Computing and Augmented Intelligence in Arizona, traktiert Sprachmodelle mit einer anderen einfachen Aufgabe. Er beschreibt der KI einen Tisch, auf dem mehrere markierte Klötze gestapelt sind – und versucht aus dem Modell die Schritte herauszufragen, die nötig sind, um die Stapelung zu ändern.
Solchen Aufgaben nähert man sich am besten, in dem man dem Modell eine „Chain of thought“ abverlangt – ihm hilft, die große Aufgabe in viele kleine Schritte zu zerlegen. Davon noch gleich mehr. Allerdings erreicht man damit bald einen Punkt, an dem man die Aufgabe eigentlich erst selbst lösen muss, wie Kambhampati in diesem Twitter-Thread beschreibt: Man muss dem Modell die Aufgabe gewissermaßen vorkauen.
Ja, aber wie lösen Sprachmodelle dann überhaupt Aufgaben?
Sprachmodelle müssen ihre Fähigkeit zum Lösen von Logikaufgaben heutzutage zuerst in standardisierten Tests beweisen. Die heißen dann „HellaSwag“ oder „MMLU“, und auch wenn die Tests gelegentlich aktualisiert werden, die Aufgaben – und die Lösungen sind bekannt. Und können damit beim Training eine Rolle gespielt haben.
Ketzerische Vermutung: KI kann dann gut Aufgaben lösen, wenn sie etwas nachplappern kann, das sie so schon mal in ihrem Training gesehen hat. „Task Contamination“ nennt man das. Wenn das aber so ist, zeichnen die standardisierten Tests ein völlig falsches Bild von den Fähigkeiten großer Sprachmodelle, und das genau ist die Position der Forscherinnen und Forscher: Wohl doch mehr stochastischer Papagei als Intelligenz – auch wenn scheinbar allwissende Papageien ja auch schon recht beeindruckend sein können, wie schon der französische Philosoph Denis Diderot festgestellt hat.
Der Hunger der Modelle
Eine kleine Beobachtung am Rande. Das Geheimnis des Erfolgs scheint auch zum Teil darin zu bestehen, dass OpenAI methodisch und zeitnah Youtube abgrast. Das geht mit Hilfe der „Whisper“-Bibliothek, die kurz vor ChatGPT veröffentlicht wurde; dass dabei das Training des kommenden GPT-4-Modells eine Rolle gespielt hat, hat der KI-Spezialist Alberto Romero damals schon vermutet (Txitter). Und ein Artikel der New York Times hat es vor einigen Wochen bestätigt.
(Das ist, ebenfalls am Rande gesprochen, dass die Sprachmodelle immer noch keinen vernünftigen Schnabeltierwitz hinbekommen – vielleicht müsste ich mal auf Youtube einen erzählen und bis zum nächsten GPT4-Update warten?)
Aber das heißt auch nicht, dass sie völlig unfähig sind. Sprachmodelle haben die Fähigkeit, sich von einem Konzept zum nächsten zu hangeln – sie dazu zu bringen, führt nachweislich zu besseren Ergebnissen, wenn auch zu keinen perfekten. Also: Bittet die KI ruhig weiter, Schritt für Schritt zu argumentieren und die eigenen Schritte zu bewerten. Aber haltet den KI-Brudi nicht für schlauer als er sein kann.
Noch ein Einschub in den Einschub: Wer nicht möchte, dass ihre Facebook-/Instagram-Inhalte von Meta zum Training generativer KI genutzt werden, kann noch bis Ende Juni 2024 widersprechen – hier für Facebook und hier für Insta. Erläuterungen dazu von den Verbraucherzentralen.
Auch lesenswert:
- Besser prompten: Gib der KI gut strukturierte ROMANE!
- Ich esse meine Worte: Das kann die KI inzwischen doch! Oder?
- Prompting-Formeln sind Bullshit. Hier ist meine.
Schreibe einen Kommentar